안녕하세요~!
저번 포스팅에 이어 2차 미니 프로젝트에 대한 회고를 포스팅해 보도록 하겠습니다.
3~5일 차 프로젝트는 면접관 Agent 구축을 진행하였는데요. 좀 더 성능을 높이면 나중에 면접 준비를 할 때 활용해도 괜찮지 않을까라는 생각이 들었습니다!!

1. 미니 프로젝트 상세
3 ~ 5일 차 : AI 면접관 Agent 시스템 구축
1) 비즈니스 문제 정의 및 목표
- 채용 과정에서 가장 부담스러운 단계인 면접을 연습할 수 있는 기회가 실질적으로 많지 않음. 그리고 면접 후 피드백을 받기도 쉽지 않기 때문에, 개인화된 질문과 답변에 대한 피드백을 해주는 AI 면접관 Agent 시스템을 구축함으로써 문제를 해결.
2) 핵심 기술
- LangGraph 기반 Agent 설계
- LLM(OpenAI / GPT-4.1-mini) 기반 질문 생성 및 전략적 응답 흐름 구성
- 이력서 요약 후 전략 수립 -> 질문 생성 -> 사용자 응답 -> 추가 질문 -> 평가 및 최종 피드백까지 구성
3) 목표
* 미션 1) AI 면접관 Agent v1.0
=> 이력서 및 자소서 Text 인식
=> 서류 분석 후 LLM 기반으로 요약 및 키워드 도출 & 질문 전략 수립
=> 답변 입력 시 답변 평가(상/중/하), 추가 질문 여부 판단, 심화질문 생성, 최종 평가 결과 출력
* 미션 2) AI 면접관 Agent v2.0
=> 모듈 고도화 작업 진행
- 사전 준비 단계 고도화 : 이력서 요약 및 전략도출 고도화
- 질문 생성 고도화 : 전략 별 참조할 질문 Vector DB 구성
- 인터뷰 진행 검토 고도화 : 기준에 따른 종료 여부 검토, 추가 질문 생성(심화 질문, 꼬리 질문 등)
- 최종 평가 피드백 고도화 : 질문과 답변에 대한 최종 평가 보고서
4) 기술 상세
- 사전 준비 단계 : 이력서 PDF 파일 요약 및 키워드 추출 ---> 질문 전략 생성(분야별 질문 세트 구성 : 인성, 역량, 직무 관련)
- 면접 단계 전체 구조
첫 질문에 따른 사용자 답변 ---> 답변 평가 및 다음 단계 결정 ---> 다음 질문(꼬리 질문 or 심화 질문) 생성 ---> 최종 피드백(보고서 출력) ---> Gradio 연결

- 인터뷰 실행 및 사전 질문 세트(build_question_strategy)
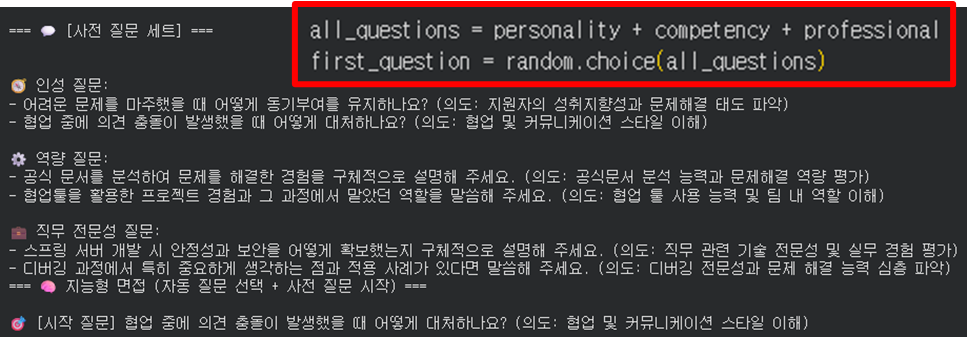
- 답변 평가(evaluate_answer)
기본 / 엄격 /관대 평가자를 시뮬레이션하여 답변 평가의 일관성 및 신뢰성 확보
3개의 평가 결과를 점수화하고 분산 분석을 통해 재검사 여부 판정
=> 평가 점수의 평균과 표준편차로 답변의 신뢰도 분석 후, 재검사 / 보완 질문 / 다음 세트 중 자동 분기


- 면접 흐름 제어(decide_next_step)
동일 주제에서 3회 이상 답변 + 점수가 높을 시(평균 2.3점 이상) -> 새로운 주제로 자동 전환
최근 답변 평균 점수 + 누적 횟수 -> 다음 면접 단계 자동 분기
요약 -> 보완 질문 -> 다음 세트 순서


- 다음 질문 생성1 (generate_dynamic_question_set)
주어진 주제에 대해 최근 2개 대화 기준으로 인성 / 역량 / 직무 전문성 3가지를 기반 질문 생성

- 다음 질문 생성2 (select_best_question)
앞서 generate_dynamic_question_set 메서드에서 생성한 질문 중 하나를 LLM이 판단하여 제일 적합한 질문을 고름. 사용자가 답변한 대답을 다시 언급함으로써 자연스럽게 질문 구성.

- 다음 질문 생성3 (generate_next_set)
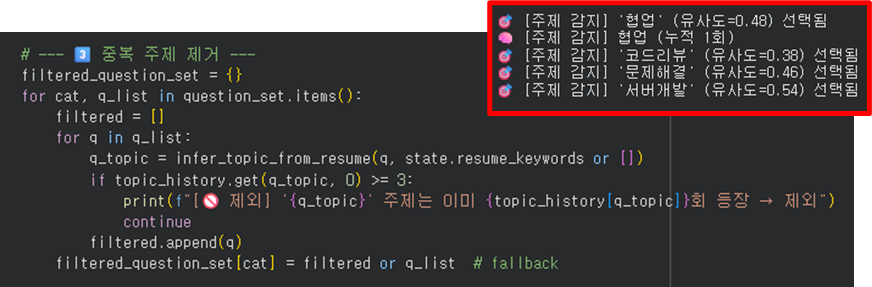
이전 대화와 주제 유사도 정도 판단 후 가장 유사도가 높은 주제를 선정.
동일 주제에 대해서는 3회 누적 시 제거 후 선택하지 못하도록 함.
남은 주제 중 유사도가 높은 주제를 선정(현재 맥락과 전혀 다른 주제가 갑자기 등장하는 것을 막기 위함)
- 인터뷰 최종 피드백 출력(summarize_interview)

- Gradio 연결(chat_interview)
사용자의 입력을 받아 Gradio 인터페이스와 연결, 답변 평가 -> 다음 질문 생성 -> 대화 갱신까지 처리

5) 기대 효과
- 실제 면접처럼 질문을 받고 답변하는 구조로 구성되어 있어 실전 인터뷰 감각 향상에 도움.
- AI 면접관으로부터 답변에 대한 피드백을 받음으로써 실전 면접에 대비 가능.
- 이력서와 자소서 정리 및 재정비 기회 마련 가능.
2. 느낀점
이번 미니 프로젝트는 AI 면접관 Agent 구축 및 성능 고도화라는 공동의 목표를 가지고 함께 협업하는 과정에서 팀워크의 중요성을 깨닫는 좋은 경험이 되었습니다. 개인 실습을 통해 각자 모델을 설계하고 에이전트를 개발하는 경험에서 실무 역량을 쌓았을 뿐만 아니라, 각 모델을 통합하여 가장 성능 좋은 단일 모델을 도출하고, 이를 공동으로 고도화하는 과정에서 더 큰 성장을 할 수 있었습니다.
저는 이 프로젝트에서 인터뷰 진행 검토 고도화 역할을 담당하며, 특히 LangGraph 그래프 통합관리와 State 통합 설계가 복잡한 멀티 에이전트 시스템에서 얼마나 중요한지 느낄 수 있었습니다.
State나 LangGraph 노드의 변경, 추가, 삭제 사항이 발생할 때마다 공유 문서를 통해 팀원들에게 즉시 공유했는데도 불구하고, 개발 과정에서 에러가 발생하여 수정하는데 어려움을 겪었습니다. 코드 통합 과정이 예상보다 훨씬 쉽지 않다는 것을 다시 한번 깨달았으며 명확하고 일관된 State 관리의 중요성을 깊이 깨달았습니다.
이러한 협업과 고도화 노력의 결과, 프로젝트 최종 발표 기회를 얻었을 때 강사님께 호평을 받는 좋은 성과를 거둘 수 있어 매우 보람차고 뿌듯했습니다. 아울러, 프로젝트의 코드 최종 검토자 역할까지 수행하면서 결과물을 전반적으로 검토하고, 실행 중 이슈 사항이 없는지 체크하는 과정을 통해 코드 전반의 흐름을 또 한 번 완벽하게 파악할 수 있었으며, 이는 AI Agent 구축에 대한 이해도를 높이는 데 큰 도움이 되었습니다. 이번 경험을 바탕으로 다음에는 더 성능 좋은 Agent를 구축해보고 싶다는 생각이 들었습니다.
'프로젝트' 카테고리의 다른 글
| KT 에이블스쿨 5차 미니 프로젝트 회고 (0) | 2025.12.26 |
|---|---|
| KT 에이블스쿨 4차 미니 프로젝트 회고 (1) | 2025.12.14 |
| [KT AIVLE SCHOOL] 3차 미니 프로젝트 회고 (0) | 2025.11.15 |
| [KT AIVLE SCHOOL] 2차 미니 프로젝트 회고(1~2일차) (1) | 2025.11.07 |
| [KT AIVLE SCHOOL] 1차 미니 프로젝트 회고 (0) | 2025.10.22 |