안녕하세요~!
드디어 에이블스쿨 2차 미니 프로젝트도 끝이 났습니다.
이번 프로젝트는 속성 기반 감성 분석(1~2일 차) 및 면접관 Agent(3~5일 차)를 직접 구축해 보았는데요!
개발하다 보니 재미도 있고 더욱 성능 좋은 AI를 만들기 위해 욕심이 생겼던 프로젝트였습니다!!
그래서 진행했던 프로젝트에 대해서 회고를 포스팅해보려고 하는데 이번 포스팅은 1~2일 차 프로젝트에 대한 회고입니다.

1. 미니 프로젝트 진행방식
저번 1차 미니 프로젝트와 동일하게 먼저 주어진 과제들을 개인이 모두 스스로 실습해 보고,
나중에 팀별로 모여 하나의 최종 산출물을 만드는 형식으로 진행이 되었습니다!
저번 1차 때보다는 좀 더 팀워크가 중요했던 프로젝트였던 만큼 저희 팀은 특히나 각자 주어진 역할을 열심히 수행하면서도
서로 부족한 부분은 도와주기도 하며 최고의 결과를 도출하기 위해 노력했습니다.
결론적으로 3~5일 차 때 진행되었던 프로젝트의 경우 발표 기회까지 주어지게 되어 강사님께 호평을 받을 수 있었습니다!!
저는 이번 프로젝트에서 PPT 일부 제작과 최종 검토자를 역할을 담당하여 소스 포함 모든 결과물들을 확인하고, 오타나 이슈사항은 없는지 점검하는 역할을 수행하였습니다.
2. 미니 프로젝트 상세
1 ~ 2일 차 : 속성 기반 감성 분석 프로젝트
1) 비즈니스 문제 정의 및 목표
- 스킨케어 및 메이크업 제품을 판매하는 가상의 뷰티 브랜드에서 특정 제품에 대한 리뷰를 다양한 속성(보습, 밀착, 향, 제형, 가격, 피부 등)에 따라 분석하여, 소비자의 감성을 파악 후 발견한 인사이트에 따라 제품 개선, 마케팅 전략, VOC 활용 체계를 구축
2) 활용 모델 : klue/bert-base , klue/RoBERTa-base
3) 핵심 기술
- 위 2) 모델 기반 파인튜닝 진행
- 리뷰 긍 / 부정 분류(속성별 감성 분류 파이프라인)
- 리뷰 데이터 구조화 및 자동 요약 / 추천 / 클러스터링 확장
4) 목표
* 미션 1) 리뷰마다 긍 / 부정 감성 분석
=> 리뷰를 긍, 부정으로 분류하는 모델 생성
=> 사전학습 모델을 파인 튜닝하여 모델 성능 높임
* 미션 2) 리뷰에 포함된 11가지 속성 검출
=> 리뷰에 포함된 11가지 속성 검출 후, 속성에 해당하는 내용이 리뷰에 등장하는지 분류 모델 생성
5) 기술 상세
- 데이터 전처리
리뷰 분류를 위한 데이터셋 구성
주어진 데이터 목표에 맞는 형태로 변환 ('[ASPECT] 속성 [SEP] 문장' 형태로 변환해 모델 입력 구성)
데이터 전처리, 가중치 설정으로 데이터 불균형 문제 해결



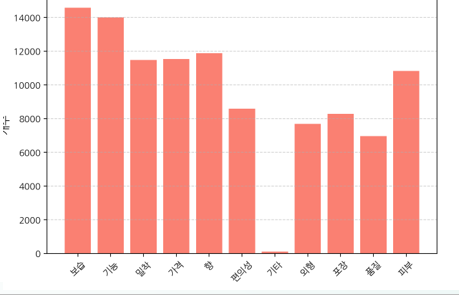
- 모델링
다중 레이블 분류 파인 튜닝 진행
10만 건 데이터셋 중 5000개 샘플링하여 수행.
하이퍼파라미터 조정하며 일반 파인튜닝 + LoRA 파인튜닝 (epochs=5로 설정 후 학습)
● 검증 데이터에 대해 모델 예측 수행 후 argmax로 0/1 변환



6) 결과
● 다만 리뷰 내용에서 단어가 직접적으로 언급이 되지 않고 다양한 단어들을 통해 나타나는 속성(편의성, 기능)은 상대적으로 예측 score가 낮음 (모델의 성능에 의존)
●평균 F1-score ≈ 0.92 이상 → 모델이 긍·부정 모두 안정적으로 예측
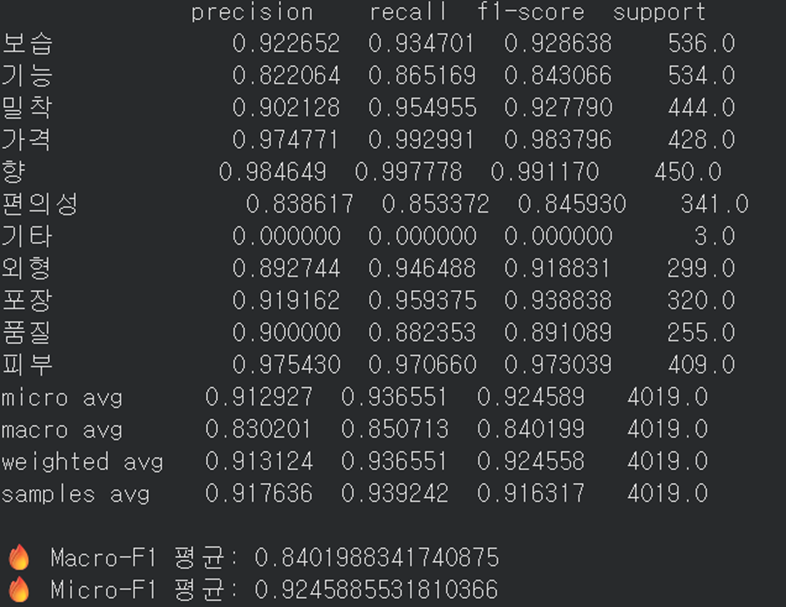
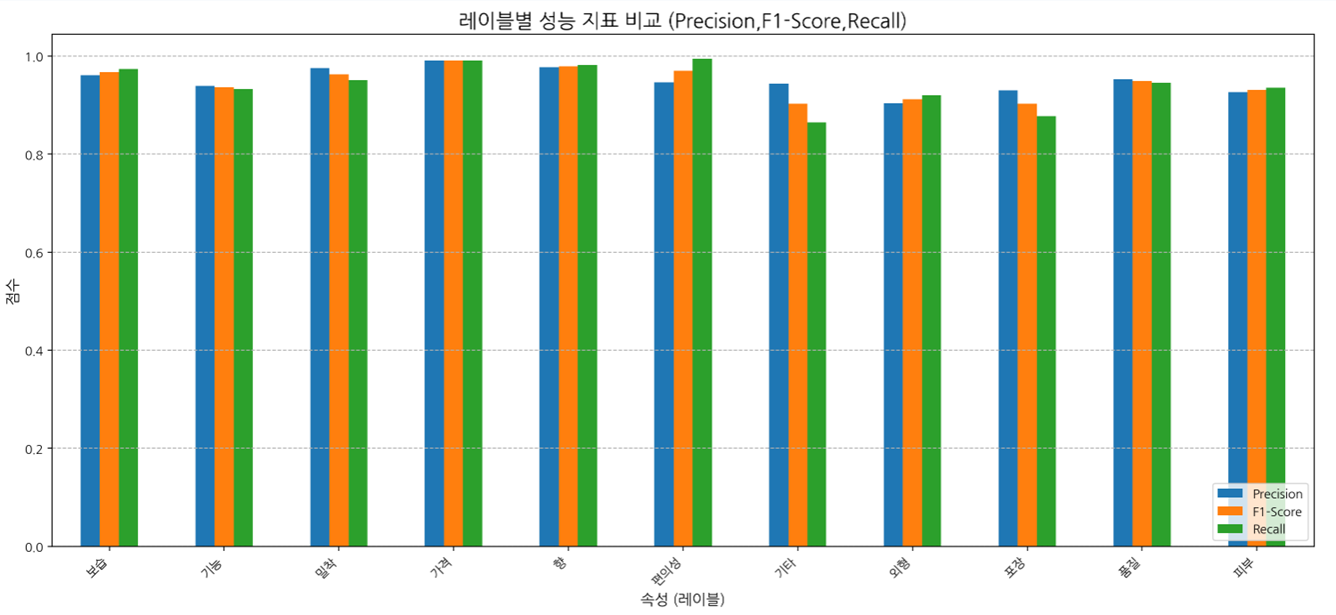
7) 비즈니스 적용점
이어서 다음 포스팅에서 3~5일 차 프로젝트에 대한 회고 참고해 주세요!

'프로젝트' 카테고리의 다른 글
| KT 에이블스쿨 5차 미니 프로젝트 회고 (0) | 2025.12.26 |
|---|---|
| KT 에이블스쿨 4차 미니 프로젝트 회고 (1) | 2025.12.14 |
| [KT AIVLE SCHOOL] 3차 미니 프로젝트 회고 (0) | 2025.11.15 |
| [KT AIVLE SCHOOL] 2차 미니 프로젝트 회고(3~5일차) (0) | 2025.11.07 |
| [KT AIVLE SCHOOL] 1차 미니 프로젝트 회고 (0) | 2025.10.22 |