안녕하세요~!
AICE Associate 시험날짜가 얼마 남지 않았습니다.
최종 모의고사도 풀어보고 AICE 샘플문제도 풀어보면서 앞서 올린 요약본에 정리하지 않았던 중요한 내용을 추가적으로 포스팅해보려고 합니다!
그리고 시험 볼 때 주의사항과 꿀팁도 공유할 생각이니 글 끝까지 읽어주시면 감사하겠습니다.

🏷️AICE Associate 추가 요약 내용 및 주의사항
1. 설치가 필요한 라이브러리의 경우 !pip install을 활용하여 설치합니다.
!pip install seaborn
import seaborn as sns
2. value_counts() : normalize = True를 주면 범주형 변수에 대해 각 범주별 비율을 확인할 수 있습니다.
여기서 * 100을 하면 백분율(%)로 변환할 수 있습니다.
df[열 이름].value_counts(normalize = False/True)
3. astype() : 바꾸고자 하는 열을 원하는 타입(int, str, float 등)으로 변환
df['열이름'] = df['열이름'].astype(type)
4. groupby() : 그룹별 집계 함수
집계 함수에 맞게 그룹별로 원하는 열을 집계
- by: 그룹의 기준이 되는 열 (여러 열의 경우, 리스트로 묶어 작성 가능)
- as_index = True / False : 그룹 기준 열을 인덱스화할지 여부
* 집계함수: sum(합), mean(평균), std(표준편차), count(개수) 등 다양
df.groupby(by=['그룹기준 열'])['집계 대상 열'].집계함수()
* 주의 : 열 하나의 groupby()의 결과가 시리즈 형태이기 때문에, sort_values() 시, by 옵션을 쓸 수 없음.
by 옵션의 경우 열이 여러 개 존재하는 데이터프레임에서만 가능
(아래 코드는 부서별 직업 만족도의 평균을 내림차순 정렬하여 첫 번째 인덱스 값(=부서)을 가져온 것)

5. get_dummies() : columns 옵션에서 컬럼값을 줄 때, 값이 하나라도 [ ] 대괄호 필수

* drop() 메서드의 경우, columns 옵션에서 컬럼값을 줄 때, 값이 하나라면 ' ' 표시하면 됨.

6. sns.heatmap(data=df[col_list].corr(), annot=True, fmt='.2f') : col_list 변수들 간 상관관계 히트맵으로 그리기

* 옵션
1) annot = True (각 셀의 값 표기 유무)
2) fmt = 'd' / fmt = '.2f' 등 (각 셀 값의 데이터 타입 설정)
3) cmap='Blues' (히트맵 색상)
3) vmin = 10 (최솟값)
4) vmax = 100 (최댓값)
5) cbar = True (colorbar 유무)
6) center=400 (중앙값 선정)
7) linewidths=0.5 (셀 사이 선 추가)

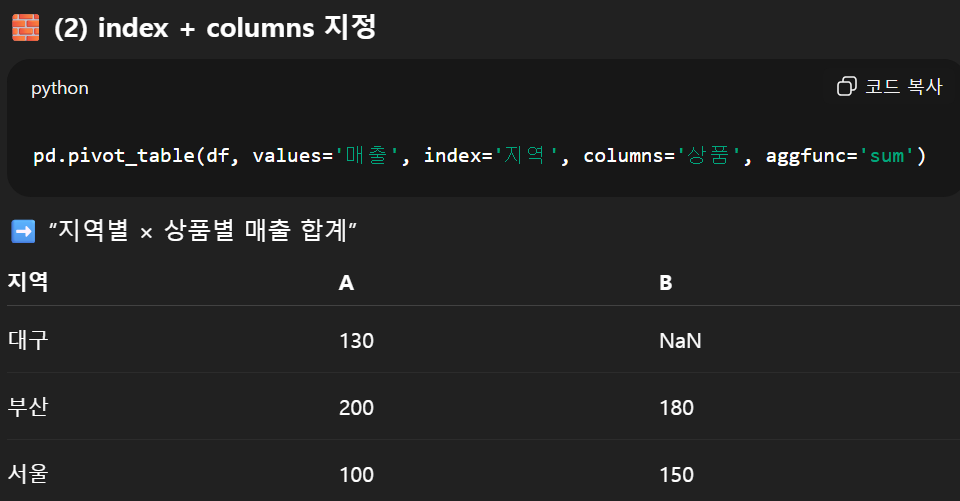
7. 피벗 테이블 : df.pivot_table()
1) seaborn (X), 데이터프레임.pivot_table() (O) / pd.pivot_table() (O)
2) 옵션
| data | 피벗할 원본 DataFrame |
| values | 집계할 열 이름 (예: '매출', '점수') 즉, 계산 대상 |
| index | 행(세로축)에 올 열 이름 : 기준이 되는 열 |
| columns | 열(가로축)에 올 열 이름 |
| aggfunc | 집계 함수 (기본값 'mean') 예: 'sum', 'count', 'max', 'min', np.median, len 등 |

- 아래 해석 : 지역에 따른 매출의 합계를 상품별로 보여주기
8. 교차표 crosstab
1) 두 범주형 변수 간의 교차 빈도표(빈도수, 교차분할표)를 만드는 함수
2) normalize 옵션을 이용하면 비율(%) 로도 변환할 수 있습니다.
3) 아래 코드 순서대로 (부서별 이직 여부의 비율(%)을 계산하는 표)
# 행(index): 부서별
# 열(columns): 이직 여부 (예: Yes / No)
# 행 기준 비율 계산
# 소수점 둘째 자리까지 반올림

9. SVM(서포트 벡터 머신) : SVR(회귀모델) / SVC(분류모델)
1) C : 오분류 허용에 대한 패널티 정도 (규제 강도)
• 값이 작으면: 규제를 덜함 즉, 오분류 많이 허용 → 과소적합 위험
• 값이 크면: 규제를 많이 함 즉, 오분류 허용 X → 과적합 위험
2) kernel = 'rbf' : 데이터를 어떻게 구분할 것인지(직선, 곡선, S자 형태의 선..)
• 'linear': 선형 경계
• 'poly': 다항식 커널
• 'rbf': 가우시안(기본값, 비선형에 강함)
• 'sigmoid': 시그모이드 커널
3) epsilon : 예측값이 실제값이 차이가 나도 허용할 오차 범위
-> SVM 회귀에서의 “허용 오차 범위”
-> 즉, SVR(Support Vector Regression)에서만 쓰이는 옵션 / 분류(SVC) 모델에는 없음.❌


10. AICE 시험에서 tensorflow.keras.layers에 Input, Dense, Dropout 중 Input이 빠져있을 경우를 보실 수 있습니다.
딥러닝 모델 선언 시, 2가지 방법이 있는데 Input()을 활용하여 입력층을 따로 선언하는 방법과
아래와 같이 Dense() 안에 input_shape 옵션을 주어 입력층을 선언하는 방법이 있습니다.
만약 시험에서 Input이 import 되어 있지 않다면, 물론 추가해서 사용해도 되지만, 되도록 아래와 같은 방법을 사용하는 것을 AICE 시험에서는 지향한다고 하니 참고 부탁드립니다.

11. 딥러닝 모델을 이용해 새로운 시뮬레이션 데이터 예측 문제 [주의]
1) 이미 모델링 전, 진행했던 스케일러를 그대로 사용해야 함.
2) 즉, 사용했던 scaler 변수를 그대로 가져와야 함.
3) 그리고 fit_transform (X) transform(O)
=> 적용한 스케일링 방식을 그대로 시뮬레이션 데이터에도 적용해야 하기 때문

12. 최빈값으로 결측치 채우기 : fillna( df['열이름']).mode()[0] ) [주의]
- mode() 결괏값이 Series 이기 때문에 최빈값을 구하기 위해서 반드시 mode() 뒤에 인덱스 [0] 지정을 해주어야 함!

13. XGBoost & LightGBM : 부스팅 계열의 대표적인 머신러닝 알고리즘 [Gradient Boosting]
1) 사이킷런 라이브러리에 포함이 안됨 [주의]
2) 옵션
n_estimators=200, # 트리 개수
learning_rate=0.1, # 학습률
max_depth=4, # 트리 최대 깊이
subsample=0.8, # 샘플링 비율
colsample_bytree=0.8, # 컬럼 샘플 비율
random_state=42




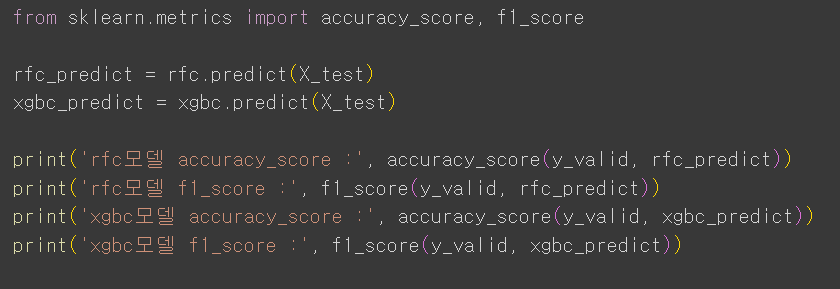
14. accuracy_score & f1_score : 정확도와 f1-score 평가지표 해석방법 중요
1) 정확도가 높게 나와도, f1_score 값이 많이 낮다면 -> 데이터 불균형 즉, 신뢰성이 낮음.
2) 즉, 정확도만 보면 안 되고, f1_score값도 함께 고려하여 성능을 평가해야 함. [주의]
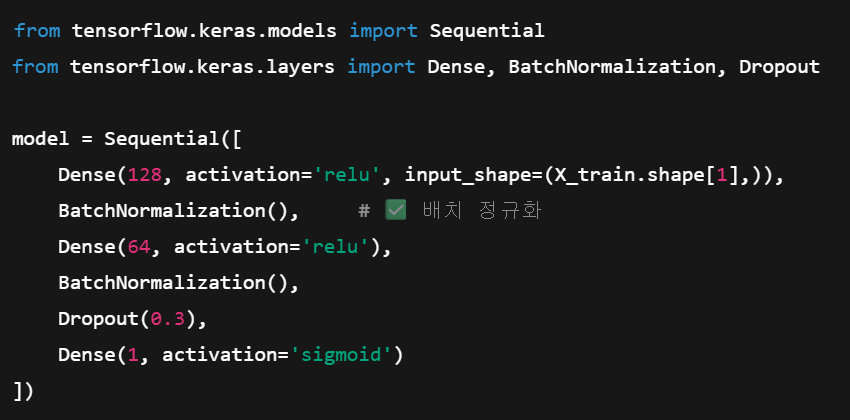
15. 배치정규화 : BatchNormalization()
1) from tensorflow.keras.layers import BatchNormalization
2) 신경망 학습 중 각 층(layer)의 입력 분포가 너무 흔들리지 않도록 미니배치 단위로 정규화(normalization)하는 기법
3) 이전 층의 가중치가 업데이트될 때마다 다음 층으로 들어가는 데이터의 분포가 계속 바뀜.
분포가 계속 바뀌면 학습이 불안정하고 느려지기 때문에 BatchNormalization이 필요
4) 모델 학습을 안정화하고, 학습 속도를 빠르게 하며, 과적합도 줄여줌.
16. 딥러닝 문제에서 validation_split에 관한 가이드가 없을 때 [중요]
validation_data=(X_test, y_valid)

17. ModelCheckpoint & Early Stopping
1) Keras / TensorFlow의 콜백(callback) 기능
2) ModelCheckpoint는 모델 학습 도중 특정 조건(예: 검증 정확도 향상 시)에 모델을 자동으로 저장하는 기능
3) Early Stopping 은 모델 학습 중 과적합 방지를 위해 검증(validation) 데이터의 성능이 더 이상 좋아지지 않으면 학습을 멈춤.
4) Early Stopping 옵션의 최적의 가중치 저장 : restore_best_weights=True
5) ModelCheckpoint(filepath, monitor, save_best_only=True)
- ModelCheckpoint 옵션의 save_best_only=True : 가장 성능이 좋은 모델 가중치만 자동으로 저장
- 매 epoch이 끝날 때마다 지정한 지표(monitor)를 확인하고, 그 지표가 기존보다 좋아지면 해당 모델 가중치를 저장
6) model.fit(callbacks=[es,mc])
- 모델 학습 시, 앞서 지정했던 Early Stopping 와ModelCheckpoint 결과를 담은 변수를 callbacks 옵션에 할당


18. 이진분류 -> 다중분류로 변환 : to_categorical (y값, num_classes=2)
1) y_train이 범주형 레이블 일 때, 이를 원-핫 인코딩(one-hot encoding) 형태로 변환
2) num_classes 옵션에 분류할 클래스의 개수를 명시
-> 이진분류(binary classification)이므로 2개 클래스(0과 1)
3) y_valid 또한 y_train에 맞춰 동일하게 원-핫 인코딩 진행
3) 출력층(Dense(2, activation='softmax')) 과 호환시키기 위해 사용
손실 함수로 categorical_crossentropy 또한 사용이 가능

'AI 관련 자격증' 카테고리의 다른 글
| ADsP 자격증 요약 정리(2) - 1과목 데이터베이스 (0) | 2026.01.27 |
|---|---|
| ADsP 자격증 요약 정리(1) - 1과목 데이터 이해 (0) | 2026.01.25 |
| AICE Associate 자격증 - 요약본 (4) 딥러닝 (0) | 2025.10.20 |
| AICE Associate 자격증 - 요약본 (3) 머신러닝 (0) | 2025.10.19 |
| AICE Associate 자격증 - 요약본 (2) 데이터 분석 시각화 (0) | 2025.10.19 |