안녕하세요!
오늘은 ADsP 자격증 1과목 데이터베이스에 대해 살펴보겠습니다.

1. 데이터베이스 특징
1) 공용 데이터
- 여러 사용자가 서로 다른 목적으로 데이터를 공용으로 이용함
ex. 하나의 고객 DB를 마케팅, 영업, CS부서가 함께 사용
2) 통합된 데이터
- 동일한 데이터가 중복되지 않도록 통합하여 데이터의 일관성을 유지
ex.고객 정보는 고객 테이블에만 있어야 함.
3) 저장된 데이터
- 컴퓨터가 접근 가능한 저장매체에 저장함.(일시적인 데이터 X)
ex. HDD, SSD, DB 서버 등
4) 변화되는 데이터
- 새로운 데이터의 추가, 기존 데이터 수정 및 삭제처리에도 현재의 데이터를 정확하게 유지하는 무결성의 특징을 가짐
- 항상 최신, 정확한 상태를 유지함
ex. 주문 취소, 주소 변경, 신규 가입같이 CRUD 발생 시 DB에 데이터가 바로바로 반영이 됨

2. 데이터베이스 가치
1) 정보 축적 및 전달 측면
- 기계 가독성 : 시스템이 이해 및 처리 가능
- 검색 가독성 : 빠른 조회와 검색이 가능
- 원격 조작성 : 네트워크 기반으로 원격 접근이 가능
2) 정보 이용 측면
- 의사결정 지원
- 데이터 분석 및 통계에 활용
- 업무 효율성 향상
3) 정보 관리 측면
- 데이터 일관성, 무결성, 보안성 확보
-- 중복을 제거하고 접근 권한을 관리
4) 정보기술 발전 측면
- 데이터베이스 기술 발전
- 빅데이터, AI, 클라우드 기술 기반
5) 경제/산업 측면
- 데이터 기반 비즈니스 창출
- 산업 경쟁력 강화
- 데이터 자산 가치 증가

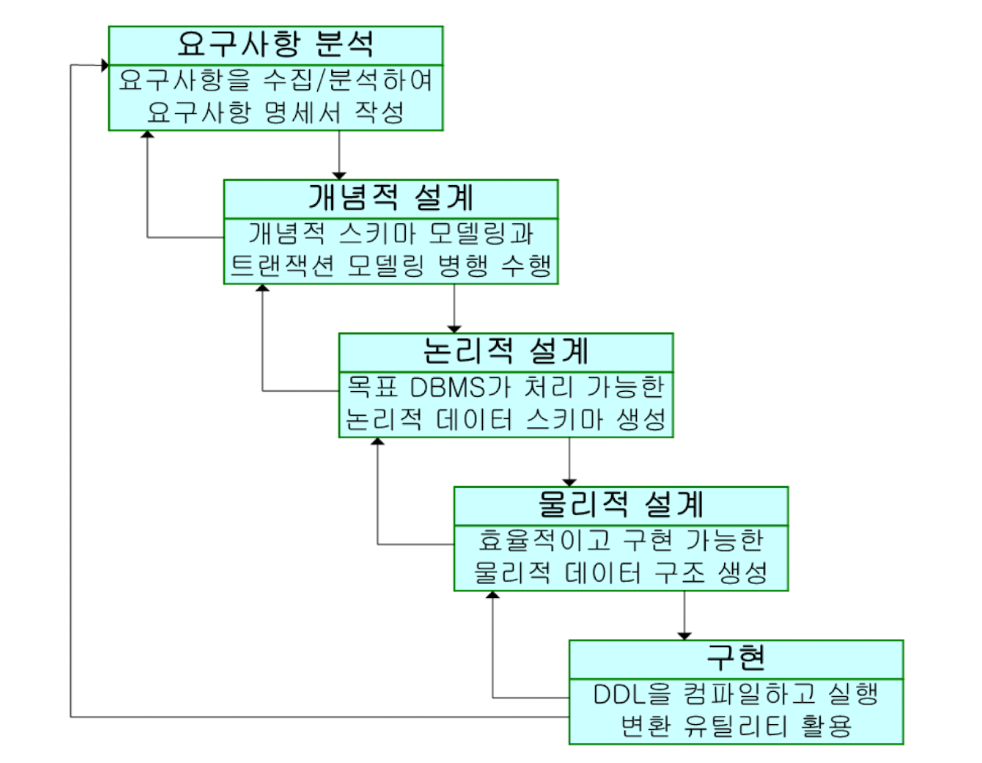
3. 데이터베이스 설계 절차
1) 요구조건 분석
- 사용자 요구사항을 수집하고 분석
- 데이터 대상, 처리 방식, 제약 조건 파악
- 무엇을 저장하고, 어떻게 사용할 것인가를 정의 (요구사항 정의서)
2) 개념적 설계 : 개념적 스키마 생성
- 현실세계를 개념적 모델로 표현
- 엔티티, 속성, 관계 정의
- 개념적 스키마 생성 (개념적 ERD)
3) 논리적 설계 : 개념적 ERD를 활용한 논리적 모델링
- 개념적 모델을 논리적 데이터 모델로 변환
- 테이블 구조 설계 및 정규화 수행
- 기본키, 외래키 정의
- 개념적 ERD 기반 논리적 모델링 (논리적 스키마 - Relation 구조 설계)
(4) 물리적 설계 : 저장 구조 설계
- 실제 저장 방식 설계
- 파일 구조, 인덱스, 저장 공간 설정
- 성능과 접근 경로 고려하여 저장 구조 설계 (물리적 스키마 - 실제 DB 테이블 설계)
4. 데이터베이스 시스템
1) DBMS
- DB를 정의, 저장, 관리, 접근할 수 있는 환경을 제공하는 소프트웨어
- 데이터 CRUD 수행, 동시성 제어, 무결성과 보안 및 백업 / 복구 관리
- 관계형 RDBMS : 정형화된 데이터를 테이블 형태로 정리(MySQL, MsSQL, Oracle 등)
- NoSQL DBMS : 비정형 데이터 저장 및 처리 (MongoDB, Redis, HBase, CouchDB, Cassandra 등)
2) DBMS 주요 기능
* SQL : DB에 접근할 수 있도록 지원하는 국제 표준 언어
- 데이터 정의(DDL) : 테이블, 뷰, 인덱스 생성 등 (CREATE, ALTER, DROP)
- 데이터 조작(DML) : INSERT, SELECT, UPDATE, DELETE
- 데이터 제어(DCL) : 권한 제어 GRANT, REVOKE + 트랜잭션 제어 COMMIT, ROLLBACK (TCL)
- 무결성 유지 : 제약조건(PK, FK)
- 보안 : 사용자 권한 관리
- 동시성 제어 : 여러 사용자가 동시에 접근
- 회복 : 장애 발생 시 빠른 복구를 할 수 있도록 함

3) 데이터베이스 스키마(= DB 설계도)
- 데이터베이스 구조와 제약조건에 대한 전반적인 명세
- 테이블 구조, 칼럼, 관계, 제약조건(PK, FK 등)
=> 스키마는 실제 데이터가 아니라 설계 정보를 말함
*외부 스키마 : 사용자 관점의 DB 구조 (뷰, 서브 스키마)
*개념 스키마 : DB 전체의 논리적 구조 (ERD)
*내부 스키마 : 물리적 저장 구조 (파일 구조, 인덱스, 저장 위치 등 물리적 구조와 저장 방식, 접근 경로에 포커싱)
ex. 개념적 설계 단계에서 개념 스키마가 도출됨 (O)
ex. 물리적 설계 단계에서 내부 스키마가 도출됨 (O)

4) 메타데이터
- 데이터를 설명하는 데이터
- 데이터 구조, 데이터 칼럼 타입, 길이, 제약조건, 테이블 생성일 등
- DB 구조를 이해하고 검색하고 관리하는 데 사용
5) 데이터 사전
- 메타데이터와 데이터 구조 정보를 저장하는 시스템 내 저장소
- 메타데이터를 보관하는 장소로, 사용자가 직접 수정할 수 없음. DBMS가 자동으로 관리
- 메타데이터 ⊂ 데이터 사전
6) 인덱스
- 정렬과 탐색을 위한 보조 도구로 성능 개선에 중요한 역할
- 실무에서도 항상 인덱스 관리에 신경을 많이 썼음. 사용자는 특히나 서비스 속도에 민감하기 때문에 인덱스를 잘 걸어두어야 함.
- 다시 말해, 데이터 검색 속도를 향상하기 위해 사용하는 자료 구조라고 보면 됨
(SELECT 성능이 올라감 / 반대로 INSERT, UPDATE, DELETE 성능은 감소)
7) 인스턴스
- 특정 시점에 실제로 저장된 데이터 값의 집합
- 타입, 구조 X, '말 그대로 데이터' 를 의미
5. 데이터베이스 활용
기업 내부 활용 데이터베이스
- OLTP : 다량의 단기 거래를 실시간으로 처리 (현재, 정형, 트랜잭션)
- OLAP : 다차원 데이터를 대화식으로 분석 (과거, 분석, 의사결정 지원)
- ERP : 인사, 회계, 생산 등 기업 내부 자원 통합 관리
- CRM : 고객 관련 데이터를 분석하여 마케팅, 고객 관리에 활용
- SCM : 외부 공급망(조달, 생산, 유통)을 통합 관리 및 최적화
=> ERP를 중심으로 SCM과 CRM이 연계됨
- RTE : 실시간 최신 데이터 기반 신속한 의사결정 지원
- KMS : 기업 내 지식, 노하우를 체계적으로 축적 및 공유
- Blockchain : 네트워크 내 모든 참여자들이 정보를 분산 저장하는 분산 원장 기술 => 중앙 관리자가 없음
- BI : 기업 데이터 기반 리포트, 대시보드 중심 분석 시각화 (과거 &현재)
=> 기업의 전략적 의사 결정에 도움을 주는 데이터 분석과 시스템
- BA : 통계, 분석 기법을 활용한 비즈니스 인사이트 도출 (미래 지향)
=> 데이터를 분석해서 인사이트를 도출하는 기법/활동

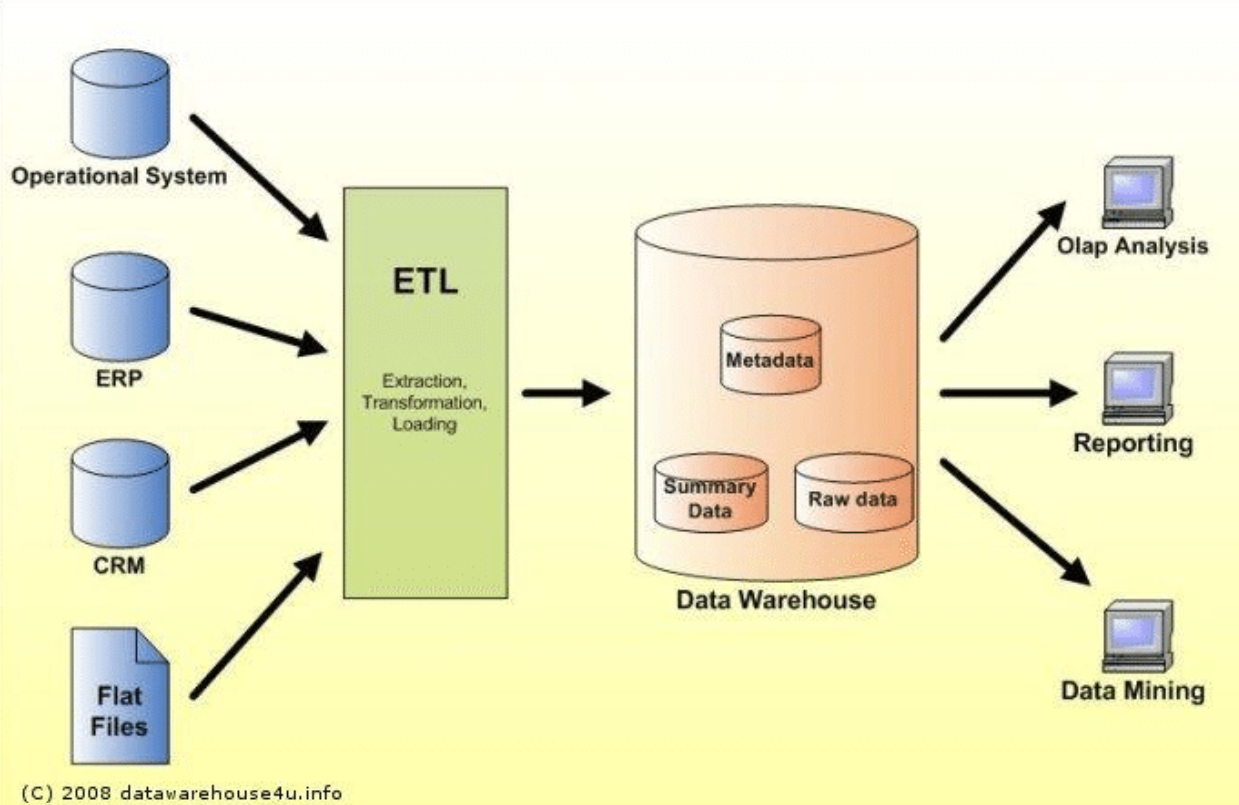
6. 데이터 웨어하우스(DW)
- 여러 DBMS의 데이터를 ETL로 추출하고 가공해서 저장
- 의사결정 지원 목적 => 여러 DBMS에서 데이터 가져와 '분석용으로 재구성한 중앙 저장소'
- 기업 내부, 외부의 다양한 데이터를 통합하여 저장하는 중앙 집중형 저장소

1) 구성요소
* ETL(실시간 X, 주기적으로 DW로 들어오는 관문)
- Extraction : 다양한 소스(DB, 로그 등) 에서 데이터를 추출
- Transform : 데이터 정제, 가공, 변환
- Load : DW에 적재

*ODS(Operational Data Store)
- 여러 DBMS에서 추출한 데이터를 임시로 저장
- DW 적재 전 중간 저장소
- 실시간 / 근실시간 데이터 처리 가능
2) DW 특징
- 주제중심 : 분석 목적 중심으로 구성 (실시간으로 변경되는 업무 중심이 아니라, 분석과 의사결정에 포커스를 둔 주제 중심)
- 데이터 통합 : 일관된 형식으로 통합하고 저장함.
- 시계열성 : 과거부터 현재까지의 히스토리를 보존함.
- 비휘발성 : 읽기 전용으로, 자주 변경되지 않음
- 스키마 온 Write : 데이터를 저장할 때 스키마를 미리 적용하는 방식
=> 실시간 갱신 X, OLTP X : DW는 OLAP 의 성격
7. 데이터 레이크(DataLake)
- 정형, 반정형, 비정형 데이터를 원형 그대로 저장하는 대용량 저장소
- 비정형 데이터를 저장하며 하둡과 연계하여 처리
- 스키마 선적용 하지 않기 때문에 유연성이 높음
- 빅데이터 분석이나 AI/ML에 활용됨
- 스키마 온 Read : 데이터를 저장할 때는 구조를 정하지 않고, 읽을 때(분석할 때) 스키마를 적용하는 방식
* 하둡(Hadoop)
- 여러 컴퓨터를 하나의 시스템처럼 묶어 대용량 데이터를 처리하는 오픈 소스 빅데이터 솔루션
- 전에 학부시절, 빅데이터 관련 수업 들었었는데, 그때 하둡 배웠던 게 기억남.
한 가지 확실한 건 MapReduce 처리가 로우 레벨의 프로그래밍에 가깝다 보니 개발 난도가 높아 쉽지 않았던 걸로 기억함...
- HDFS : 분산형 파일 저장 시스템(대용량 데이터 저장)
- MapReduce : 분산된 데이터를 병렬로 처리(Map -> Reduce 단계로 처리함)

'AI 관련 자격증' 카테고리의 다른 글
| ADsP 자격증 요약 정리(4) - 2과목 데이터 분석 기획 (0) | 2026.02.04 |
|---|---|
| ADsP 자격증 요약 정리(3) - 1과목 빅데이터 (0) | 2026.02.02 |
| ADsP 자격증 요약 정리(1) - 1과목 데이터 이해 (0) | 2026.01.25 |
| AICE Associate 자격증 시험 총 정리 및 주의사항 & 꿀팁 (0) | 2025.10.23 |
| AICE Associate 자격증 - 요약본 (4) 딥러닝 (0) | 2025.10.20 |