안녕하세요~!
오늘은 AICE Associate 자격증 시험을 앞두고 공부한 내용을 요약해서 올려보려고 합니다.
이 글은 어느 정도 파이썬과 머신러닝, 딥러닝에 대한 기초가 있으신 분들이 요약본으로 간단하게 정리하고 싶은 분들께 추천드립니다!
기초 내용을 공부하고 싶으신 분들은 제 티스토리에 다른 글들 보시면 자세히 설명해 놓았으니 참고해 주시기 바랍니다.

1. 데이터 처리
(1) 조회 방법 정리
- df.loc[:, 'score'] -> df['score'] // 기본적으로 행 생략 불가 -> 행 생략하고 싶을 시, loc 제외하고 쓸 수 있음.
- df.loc[:, ['name', 'sex'] ] -> df[ ['name', 'sex'] ]
- df.loc[1, :] -> df.loc[1] // 열은 생략이 가능
- df.loc[[1,2,3], :] ->df.loc[ [1,2,3] ]
- df.loc[df['score'] > 60, :] -> df.loc[ df['score'] > 60 ] // 조건이 들어갈 때도 마찬가지로 열은 생략 가능
- df.loc[ (df['score'] > 60) & (df['age'] > 20) , :] -> df.loc[ (df['score] > 60) & (df['age'] > 20) ]
- df.loc[(df['score'] >= 60 ) & (df['age'] < 20), ['name', 'age', 'score']] //행,열 모두 값이 있기 때문에 생략 불가
(해석 : 점수가 60점 이상이고, 나이가 20 미만인 데이터를 name, age, score 컬럼만 보여주기)
- df.loc[ df['score'].between(30, 70), : ] -> df.loc[ df['score'].between(30, 70) ] // 30 ~ 70점 사이 데이터 조회
- df.loc[ df['score'].isin([30,70]), : ] -> df.loc[ df['score'].isin([30,70]) ] //30 혹은 70점 데이터 조회
(2) 열 이름 변경
- df.columns = [리스트]
(모든 열 이름 변경 시 사용합니다)

- df.reame( columns = {'기존 열 이름1' : '변경할 열 이름1', ' 기존 열 이름2' : ' 변경할 열 이름2' ... } , inplace=True )
(지정한 열 이름 변경)

(3) 열 추가
- 기존에 없는 열 변경 = 추가 (맨 뒤에 추가됨, 원하는 위치에 추가 불가)
- 기존에 있는 열 변경 = 수정

- 원하는 위치에 열 추가 방법 : insert(열 번호, '추가할 열 이름', 추가한 열에 넣어줄 데이터)

(4) 열 삭제
- drop('열 이름', axis=1) 혹은 drop(columns='열 이름')
- axis=0 : 행 삭제(기본값)
- axis=1 : 열 삭제

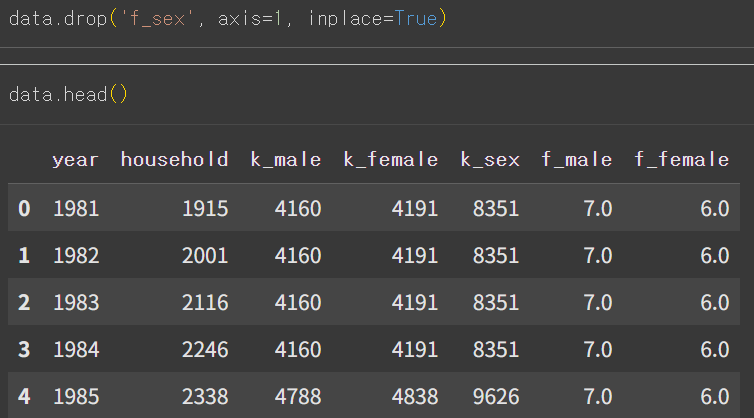
- 열 2개 삭제(리스트로 묶어주기)

(5) 범줏값 변경
* 범주형 값을 다른 값으로 변경 메서드 2가지
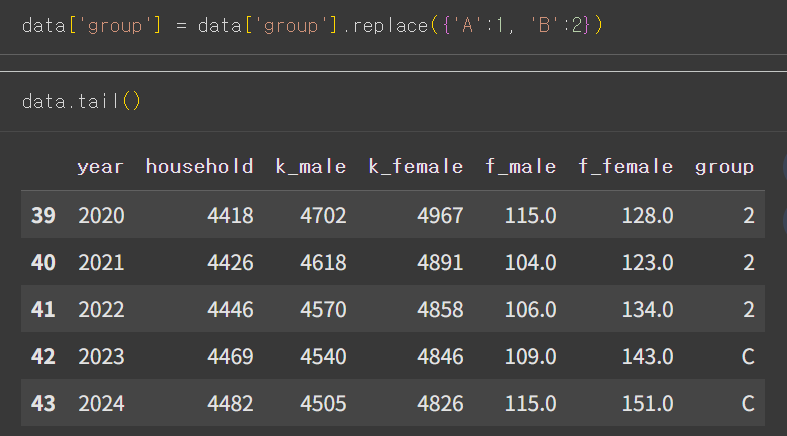
- map() : 매핑되지 않으면 NaN
- replace() : 매핑되지 않으면 원래값
- 먼저 data['group'] 이라는 범주형 데이터 열 추가
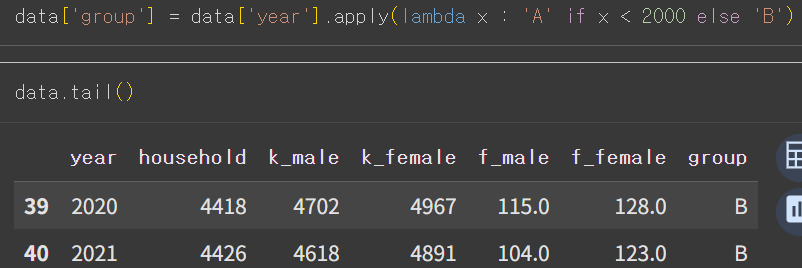
- 매핑되지 못한 값 확인을 위해 일부 값 C로 변경
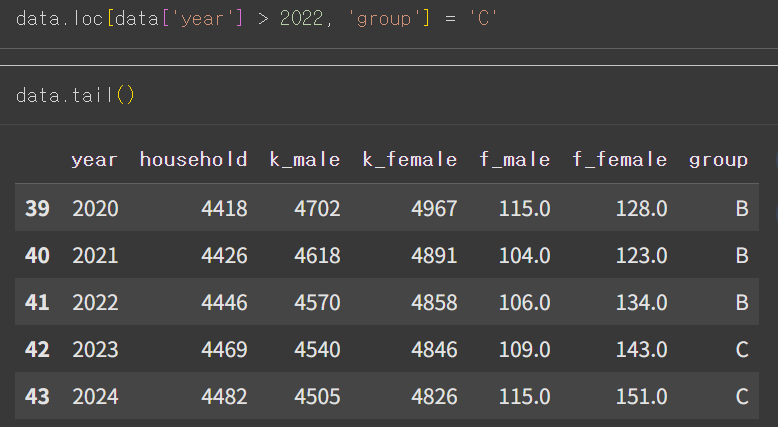
- map() 적용 결과, group 열 값이 C였던 열은 결측치가 됨.

- replace() 적용 결과, group 열 값이 C였던 열은 원래 값이 됨.
(6) 데이터프레임 합치기
- concat()
인덱스 값 기준으로 두 데이터프레임 합치기 가능
* 방향 옵션
- axis=0(기본값) : 행으로 합치기
- axis=1 : 열로 합치기
* 방법 옵션
- outer : 모든 행과 열 합치기
- inner : 매핑되는 행과 열만 합치기
- ignore_index=True : 기존 인덱스 무시하고 0부터 다시 인덱스 재생성
(실습)
* df1은 2015 ~ 2025년도 데이터
* df2는 2010 ~ 2020년도 데이터
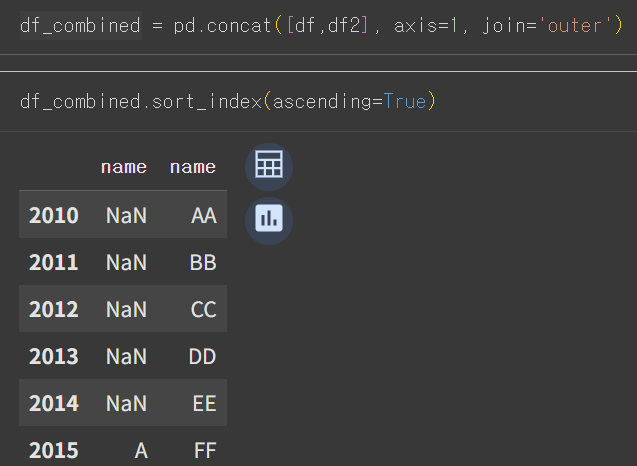
- axis=1 이므로 df1의 name 열 옆에 df2의 name열이 붙어서 하나의 테이블로 합쳐짐.
- outer 옵션을 주었기 때문에 모든 행과 열이 합쳐짐.
그래서 df1에 없는 2010~2014년 데이터는 NaN
df2에 없는 2021~2025년 데이터는 NaN
- axis=0의 경우, 행이 합쳐지기 때문에 df1의 모든 행과 df2의 모든 행이 출력됨.
아래 예제에서는 다른 컬럼이 없어 단순히 모든 행이 출력되었지만,
서로 다른 컬럼이 존재할 경우, 해당 컬럼에 대해 양 테이블에서 존재하지 않는 값의 경우 outer 옵션에 의해 각각 NaN 값 출력됨.

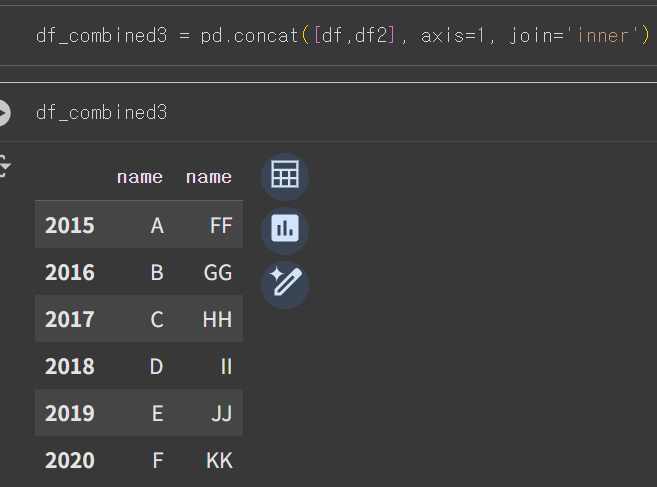
- axis=1 옵션이므로 df1의 name열과 df2의 name 열이 나란히 붙어 하나의 테이블로 합쳐짐.
- inner 옵션을 주었기 때문에 모든 행이 아닌, df1과 df2가 서로 매핑되는 행만 출력됨
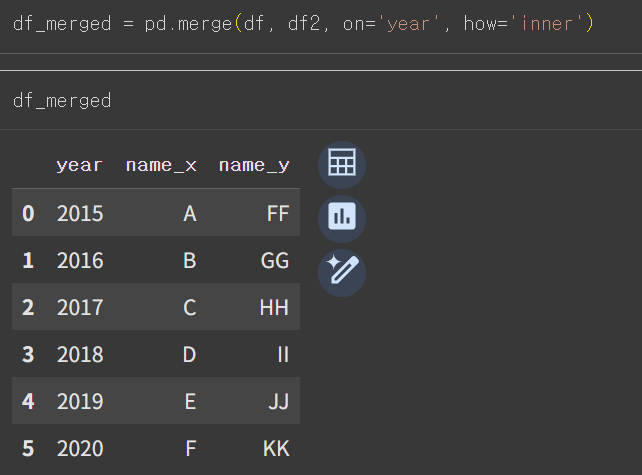
- merge() : 두 데이터프레임을 지정한 키 값을 기준으로 병합
- on 옵션에 병합 기준이 될 키 값(열 이름)을 써줌.
- how 옵션은 left / right / outer / inner 를 써줌.
DB에서 join 과 비슷하게 작동한다고 생각하면 됨.
- left join은 왼쪽 데이터프레임을 기준으로 병합,
- right는 오른쪽 데이터프레임을 기준으로 병합.
* key를 'year' 열로 잡고 outer join

* key를 'year' 열로 잡고 inner join
지금까지 데이터 처리에 관해 내용을 정리해 보았습니다.
다음 포스팅에는 데이터 분석과 관련해서 요약본을 포스팅해보겠습니다!

'AI 관련 자격증' 카테고리의 다른 글
| ADsP 자격증 요약 정리(1) - 1과목 데이터 이해 (0) | 2026.01.25 |
|---|---|
| AICE Associate 자격증 시험 총 정리 및 주의사항 & 꿀팁 (0) | 2025.10.23 |
| AICE Associate 자격증 - 요약본 (4) 딥러닝 (0) | 2025.10.20 |
| AICE Associate 자격증 - 요약본 (3) 머신러닝 (0) | 2025.10.19 |
| AICE Associate 자격증 - 요약본 (2) 데이터 분석 시각화 (0) | 2025.10.19 |