안녕하세요!
오늘 포스팅은 Object Detection(객체 탐지)과 YOLO 원리 및 주요 개념에 대해서 살펴보겠습니다.

1. 이미지 분류 및 탐지 종류
1) Image Classification(이미지 분류)
- 이미지 전체에 대해 하나의 클래스(Label)를 예측
- 이미지 내 주 객체 1개를 찾음.(객체의 위치에는 관심 X, 객체가 무엇인지가 중요)
=> 즉, 경계 박스 정보 없이 이미지 전체에 대한 단일 분류 수행
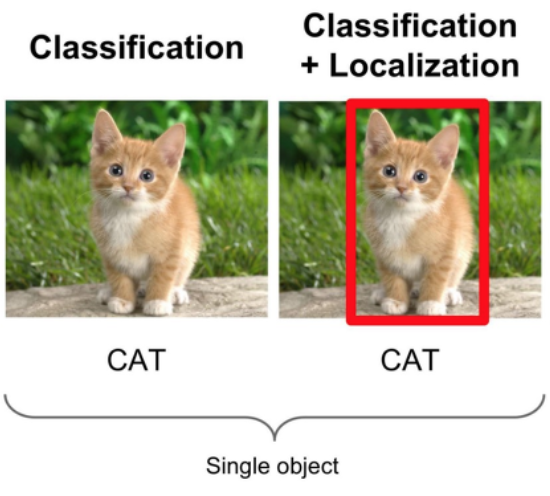
2) Image Classification + Localization
- 1) 번 방식과 함께 사용되며, 단일 객체의 위치(Bounding Box) 정보만 제공. 실무에서는 많이 쓰이지 않는 방식.
- 이 방식 또한 객체 1개를 대상으로 함.
3) Object Detection(객체탐지)
- 다중 레이블 분류에 해당(한 이미지 내 객체 여러 개 존재)
- Bounding Box(경계박스)로 객체의 위치를 찾고, 객체가 무엇인지 예측
- 경계 박스 좌표 예측 + 각 객체의 클래스 예측
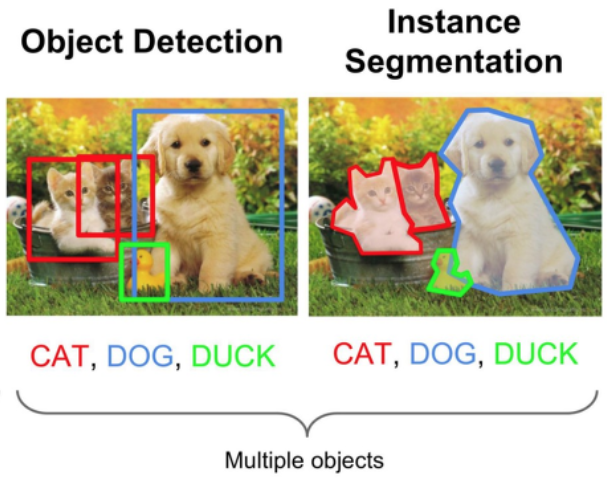
4) Instance Segmentation
- 객체가 아닌 픽셀 단위로 구분 => 픽셀 단위이기 때문에 연산량이 많음
=> 각 객체별로 픽셀 단위 영역 구분
- 바운딩 박스 (X)
- 동일 클래스라도 개별 객체로 보고 구분함(개 1 바둑이, 개 2 바순이, 개 3 인절미 친구들...)
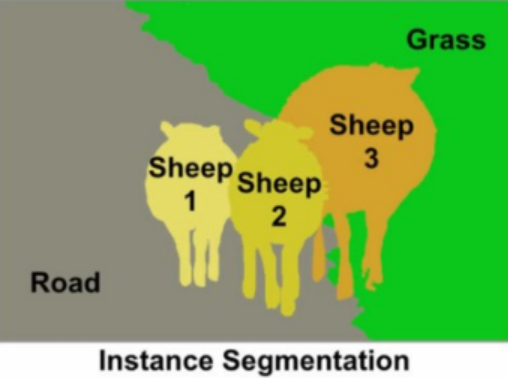
5) Semantic Segmentation
- 4)와 동일하게 객체가 아닌 픽셀 단위로 구분
- 바운딩 박스 (X)
- 동일 객체 구분(X) => 바둑이, 바순이, 인절미 모두 그냥 같은 개임.

2. YOLO의 개념
YOLO(You Only Look Once) 란 CNN기반으로 만들어진 모델로, Object Detection의 대표적인 모델.
객체 탐지 대표 모델로 YOLO 뿐만 아니라 R-CNN 계열도 있음.
R-CNN의 경우, 같은 이미지를 여러 번 보고 처리해야 한다는 한계점 존재.
연산량이 많고, 속도가 매우 느리며, 실시간 탐지가 어렵다는 단점을 지님.
=> YOLO는 이러한 R-CNN의 한계점을 개선하여 이미지를 한 번만 보고도 Bounding Box 좌표 예측과 클래스 예측을 한 번에 수행할 수 있음.(전체 이미지를 한 번에 처리하므로 속도가 매우 빠름)
- 경계 박스 4개 좌표 예측의 경우, 회귀 모델 기반. => 오차 : MSE 측정
- 객체가 존재하는지의 여부는 이진 분류 모델 기반. => 오차 : Binary Categorical Crossentropy 측정
- 각 객체가 어떤 클래스인지 클래스 예측의 경우, 다중 분류 모델 기반. => 오차 : Categorical Crossentropy 측정
3. YOLO의 원리

1) 이미지를 여러 개의 Grid Cell로 나누어 각 셀마다 인덱스 지정 (셀 별로 객체를 찾음)
- 입력(원본) 이미지를 S X S 크기의 그리드로 분할(격자 나누기)
- 각 Grid 셀이 자신의 영역 내에서 객체 탐지
- 한 객체가 여러 grid에 걸쳐 있을 수도 있음 => 객체의 중심이 속한 Grid Cell이 그 객체를 예측
2) 각 Grid Cell에서 Bounding Box와 클래스 Confidence Score 예측
=> 중심점을 기반으로 경계 박스 좌표 위치를 예측(회귀 모델링)
=> 예측한 여러 개의 경계 박스 중 객체를 예측(분류 모델링)
Bounding Box : 하나의 Object가 포함된 최소 크기의 박스로, (x, y, w, h, confidence)로 구성됨.
- (x_center, y_center) : 객체 중심의 상대적 좌표(Grid Cell 내부 기준)
- (width, height) : Bounding Box의 너비와 높이(전체 이미지 대비 상대값)
- confidence : 박스 안에 객체가 있을 확률 X 박스의 정확성(IoU)
=> YOLO는 위 예측을 CNN의 한 번의 Forward Pass로 모든 객체 탐지를 수행함.
각 Grid Cell에서 Bounding Box를 예측할 때, (x_center, y_center, width, height) 좌표를 예측하여 MSE 오차값을 최소화
- 우리는 x min, y min, x max, y max 값으로도 Bounding box 파악 가능

3) 최종 예측(Final Detections)
- 각 Grid Cell이 예측한 B개의 Bounding Box 중 가장 신뢰도 높은 것만 택
(Confidence Score가 낮은 박스는 제거)
- NMS(Non-Maximum Suppressions)를 적용하여 중복된 박스 제거
- 최종적으로 정확한 경계 박스와 클래스가 남아 객체를 올바르게 탐지가 가능
4. YOLO 모델 평가
1) IoU(Intersection over Union)
- Bounding Box가 정확한가?
- 예측된 Bounding Box와 실제 Bounding Box의 겹치는 정도(중복 허용 정도)
=> 여기서 실제 Bounding Box는 Ground Truth Box(=정답 박스 = Target = Label = 실제값) 라 부름.
=> 두 박스의 중복 영역 크기 통해 측정(0 ~ 1 사이 값)
IoU = 두 박스의 교집합 / 두 박스의 합집합
겹치는 영역이 넓을수록 1에 가까운 값 => Ground Truth Box 기준으로 오차 줄여나감(학습)
IoU > 0.5 정도 -> 올바른 탐지(True Positive, TP)라고 봄.

2) Confidence Score(신뢰점수)
- Bounding Box 안에 객체가 존재하는가?(박스 내 객체 존재 확률 신뢰도)
- Bounding Box가 정확한지, 그리고 그 안에 객체가 존재하는지 평가하는 지표
=> 예측한 경계 박스 안에 객체가 존재할 확률로, 이 박스 안에 객체가 있을 확률이 얼마나 높은 지를 수치화한 값
Confidence = P(class | object) X IoU
- P(class | object) : 해당 Grid Cell 안에 객체가 존재한다면, 그 객체가 우리가 찾는 Class일 조건부 확률
- Confidence Score가 낮은 Bounding Box를 NMS(필터링)하여 최종 결과 도출
* NMS(Non-Maximum Suppression)
- 모델에서 중복된 Bounding Box 제거하고, 가장 신뢰도 높은 박스만 남기는 과정
- 같은 객체를 여러 개 경계 박스로 탐지했을 때, 가장 확신하는(확률이 높은) 진짜 박스만 남기고 나머지는 제거
- Confidence Score + IoU 기반 동작
* NMS 과정 순서
1 > Confidence Score 임계 값 이하의 Bounding Box 제거
2 > 남은 경계 박스 Confidence Score 기준 내림차순으로 정렬
3 > 예측한 값 중 Confidence Score가 가장 높은 첫 번째 박스를 선택하고, 첫 번째 박스가 기준이 되어 나머지 다른 박스들과 모두 IoU 비교
4 > 선택한 박스와 IoU(겹치는 정도)를 계산하여, IoU 값이 임계 값 이상인 박스들 제거
(겹친 박스 중 서로 다른 객체일 경우 함부로 버리면 안 되므로 진행하는 절차)
IoU >= 임계 값(보통 0.5 ~ 0.6) : 많이 중복되므로 같은 객체로 판단 후 제거
IoU < 임계 값 : 중복이 적으므로, 다른 객체일 가능성이 있다고 판단하여 유지
5 > Bounding Box가 하나 남을 때까지 반복 수행

3) 분류 문제 평가 지표들(Recall, Precision, AP, mAP)
- 객체는 Target Class인가?
- 탐지 정확도와 재현율의 종합 평가
Precision(정밀도)
=> 탐지한 객체(TP + FP) 중에서 정답(실제 객체, TP)인 비율
- Precision 이 높음 : 잘못된 탐지(오탐) 확률 적음. (정확한 탐지만 수행)
- Precision 이 낮음 : 잘못된 탐지(오탐) 확률 높음. (쓸데없는 경계박스가 많음)
Recall(재현율)
=> 실제 객체(TP + FN) 중 정확한 탐지(TP)를 한 비율
=> 탐지 실패(FN)를 얼마나 줄였는지 평가하는 지표
- Recall이 높음 : 실제 객체를 놓치지 않고 잘 탐지. 즉, 미탐이 낮음.
- Recall이 낮음 : 탐지해야 할 객체를 많이 놓침.(FN이 많음) 즉, 미탐이 높음.

< Confidence Score의 임계값에 따라 성능이 아래와 같이 달라짐. >
* Confidence Score의 임계값을 높이면
- 정확하다고 확신하는 즉, 신뢰도가 높은 Bounding Box만 유지하고, 신뢰도가 낮은 탐지는 버림.
=> 확실한 박스만 잡으려 하니 오히려 탐지를 놓치는(미탐 증가) 박스들이 생김
- 오탐(FP)이 줄어 Precision 이 증가
- 미탐(FN)이 증가 Recall 감소
* Confidence Score의 임계값을 낮추면
- Confidence Score가 낮아도 Bounding Box 대부분을 탐지 결과로 남김.
=> Bounidng Box를 많이 남겨둠. 잘못 탐지한 박스들(오탐)도 얻어걸려 남아있게 됨.
- 오탐(FP)이 증가하여 Precision 이 감소
- 미탐(FN)이 감소하여 Recall 증가
AP(Average Precision)
- 커브 아래 면적(AUC, area under curve)
- 임계 값을 조정할 필요 없이, 모든 임계값에 대한 Precision과 Recall값을 그래프로 그려 모델 성능 평가
(임계값에 영향받지 않고, 전체를 다 고려한 성능 평가 방식)
- AP는 각 클래스별로 구하게 됨.
- AP가 높을수록 좋은 모델(좌표 Precision = 1, Recall = 1)에 가까워지기 때문

* Precision - Recall Curve(위 그래프)
- Confidence Score 임계 값을 0 ~ 1까지 조금씩 움직여 조정해 가면서 Recall과 Precision을 그래프로 그림.
- 임계 값에 따라 Recall과 Precision은 모두 달라짐.
mAP(mean Average Precision)
- 각 클래스의 AP의 평균
=> 각 클래스 별 AP를 클래스의 개수로 나누어 평균을 구함.
'AI 시각지능 & 멀티모달' 카테고리의 다른 글
| AI 시각지능 Instance + Semantic Segmentation(이미지 분할) (0) | 2025.11.17 |
|---|---|
| AI 시각 지능 YOLO 모델링 (0) | 2025.11.10 |
| 이미지 처리 기초 개념과 CNN (0) | 2025.11.09 |