안녕하세요!
오늘은 컴퓨터 비전(CV : Computer Vision) 관련 개념과 CNN에 대해 살펴보겠습니다.

1. 컴퓨터 비전(Computer Vision)
- 사람이 사물을 인식하듯이, 컴퓨터가 이미지를 분석하고 이해하는 기술로 시각지능이라고도 함.
- 카메라, 센서 등 디지털 신호를 통해 입력된 이미지 데이터를 해석하여 의미 있는 정보 추출

2. 컴퓨터 이미지 인식 과정
1) 이미지 입력
- 카메라나 파일 등을 통해 픽셀 단위로 이미지 수집 (CNN에서 픽셀들이 담긴 지역적 덩어리가 특징임)
- 여기서 픽셀은 0 ~ 255 숫자로 구성
- 색상(RGB), 밝기(그레이 스케일) 등의 기본 정보로 변환
2) 데이터 전처리
- 노이즈 제거 : 불필요한 데이터 제거
- 정형화(크기 조정) : 모델이 처리할 수 있는 해상도(Height X Width)로 조절
- 정규화(스케일링) : 색상, 밝기 값의 범위 조정
=> mnist 다중분류모델의 경우 load시 2차원(28 X 28)으로 구성 ---> 이미지는 3차원이므로 reshape를 통해 3차원으로 변환해 주어야 함.
- 반전(Black <-> White) : 255 - img
- 이미지 사이즈 resize
- 학습 시 구조로 reshape
3) 특징 추출
- 모서리, 패턴 등 사물의 특징 추출
- CNN(합성곱 신경망)을 활용해 자동으로 특징 학습 (필터가 여러 개 픽셀 덩어리를 하나의 특징으로 추출)
4) 분류 및 인식
- 딥러닝 기반의 모델(CNN 등)로 사물을 분석하고 분류함.
5) 결과 출력
- 예측된 결과를 확률 값과 함께 출력
- Object Detection(객체 인식) 혹은 Segmentation(분할) 로도 활용 가능

3. CNN 개념
- 특정 물체(Target)를 파악하기 위해서는 해당 물체의 부분적인 특징(Feature)으로부터 얻은 데이터를 보고 파악 가능
- 예를 들면, 고양이를 눈, 귀, 수염 등의 지역적인 부분 특성을 통해 알 수 있음.
=> 특정 부분(영역)을 잘 캐치하는 필터가 필요!
필터는 왼쪽 위 끝에서부터 오른쪽으로 이동하며 특징을 찾음.
오른쪽 끝까지 이동했다면 한 칸 내려와 왼쪽 끝에서부터 다시 반복하며 특징 추출
필터 내 가중치 존재
(객체의 특정 부분 발견 시 숫자값이 커지며, 발견되지 않으면 0에 가까운 값을 반환)
결론적으로 객체를 찾는 데 오차를 최소화하는 지역적 특징을 추출하는 필터를 만드는 과정을 컴퓨터 비전에서의 학습 과정으로 보면 됨.
예측과정은 학습된 필터로 동일 객체가 담긴 새로운 사진을 보여주었을 때 특징을 추출해 객체를 판별해 내는지 예측.
4. CNN 구조
CNN 딥러닝 학습 과정에서 필터의 개수는 점점 늘어나고, 필터의 사이즈는 반대로 점점 줄어듦.
[예시] 28 X 28 X 1 -> 32 X 28 X 28 -> 32 X 14 X 14 -> 64 X 14 X 14 -> 64 X 7 X 7 -> 128 X 7 X 7 -> 128 X 3 X 3 -> 256 X 1 X 1(종료) => 결론 : 28 X 28 사이즈의 한 이미지는 256개의 특징으로 파악 가능

1) input_shape
- 분석(예측) 단위인 이미지 한 장의 크기 => 입력받는 이미지 사이즈
- 픽셀 사이즈, (Height X Weight XChannel)로 표기
- 채널값(흑백 = 1, 컬러 = 3)
=> 흑백의 경우, 0이 검은색 / 1이 흰색
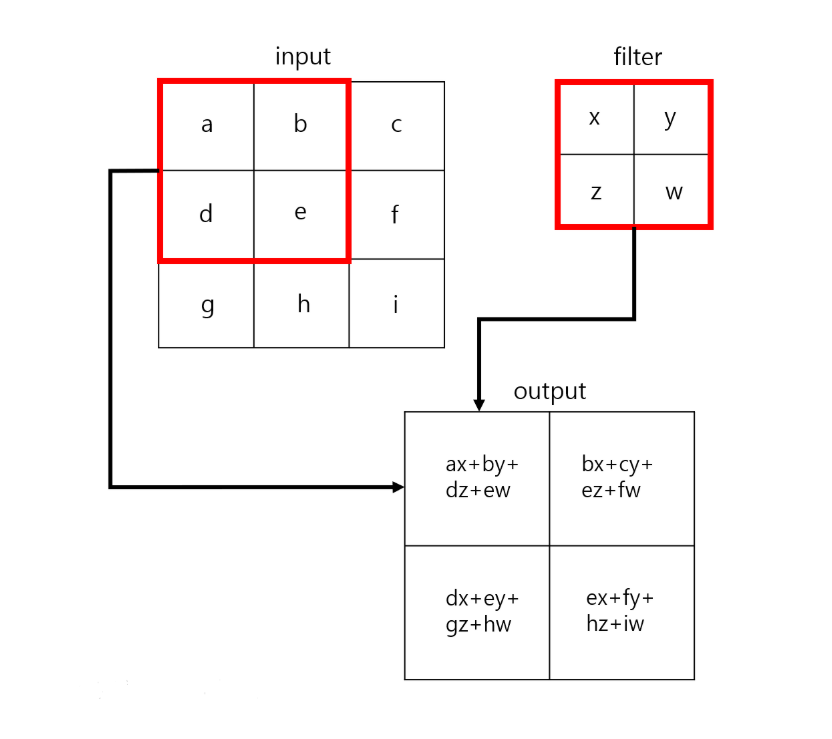
2) CNN Layer(= 합성곱 층)
- 필터로 데이터에 담겨 있는 지역적인 특성(Local feature)을 뽑는 과정
- Conv2D() 메서드를 통해 수행
Conv2D(32, kernel_size=(3,3), input_shape=(5,5,1), padding='same', strides=(1,1), activation='relu')
=> 위 코드 예시에서 필터(커널) 수는 32개
kernel_size=(3,3)은 세로 크기 3, 가로 크기 3인 커널 사이즈 지정을 의미
가로와 세로의 길이가 같을 시, kernel_size = 3으로도 표기 가능
=> 필터가 2차원으로 이동하며 합성곱 연산을 수행하여 Feature Map(특징 맵) 생성(필터 32개 = 특징맵 32개)
컬러 이미지 1장 (28,28,3) ----- 32개 필터(+padding) ----> 특징맵 32개 (32,28,28)
- 이미지는 3차원 구조 -> 필터가 2차원이므로 필터를 거친 특징맵 또한 2차원
- 컬러 이미지의 경우 채널 3개(R, G, B)에 필터를 동시에 적용
=> 채널(R, G, B) 각각에 대해 합성곱 연산을 한 후, 결과를 모두 더해 feature map을 생성
- padding = 'same' 옵션이 있기 때문에, 사이즈가 그대로 28 X 28. 만약 이 옵션이 빠져있다면 사이즈는 줄었을 것.
- 필터에는 각각 가중치가 담겨 있음.
- 합성곱 연산의 원리 : 찾고자 하는 값일 경우 숫자가 더 커지고, 찾지 않는 값일 경우가 결괏값이 더 작아지는 원리를 활용
* CNN Layer도 마찬가지로 은닉층(Hidden Layer)이기 때문에 Conv2D 메서드에서 활성화함수인 activation='relu'를 작성해주어야 함.
* strides = (1,1)
- strides = 1로도 표기 가능. (1이 기본값이라 생략 가능)
- 가로 1칸, 세로 1칸씩 이을 의미
- 필터 이동 시, 몇 칸 이동할 건지 이동 간격 결정
* padding = 'same'
- 합성곱 연산 수행 시, 가장 테두리에 있는 Input의 커널들의 경우, 연산에 1번밖에 참여를 못함.
- 만약 끝에 있는 커널들에 중요한 정보가 담겼다면 반드시 다른 커널들과 동일한 횟수로 연산에 참여해야 올바른 결괏값 도출 가능.
- 합성곱 수행 결과 Output(특징맵) 도 Input과 동일한 사이즈로 출력되도록 해주는 옵션
(Size 유지를 위해 이미지 둘레에 0으로 덧대기)
- padding = 'same'을 해주지 않으면, 당연히 사이즈가 줄어듦.

3) Max Pooling Layer
- 뽑은 특징을 요약(압축)
- MaxPooling2D() 메서드를 통해 수행
- MaxPooling의 경우 말 그대로 최댓값만 뽑아서 특징이 가장 크게 나타나는 데이터로 요약한 것을 의미.
* (32,28,28) ----- MaxPooling ----> (32,14,14)
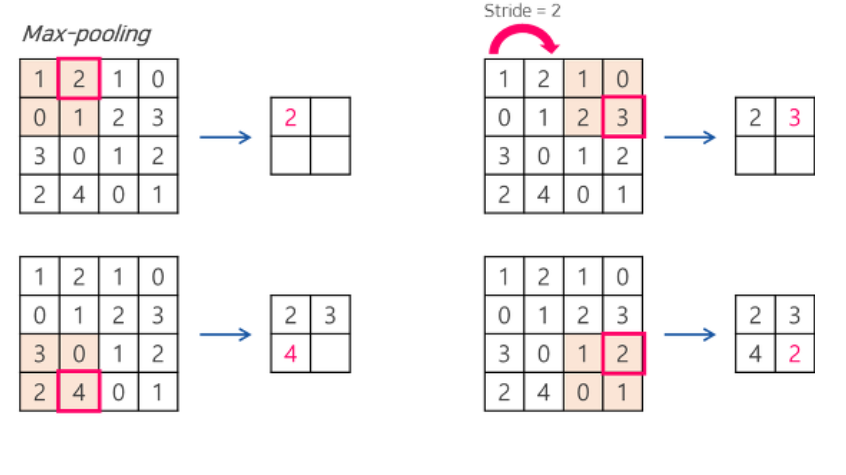
- Conv2d와 쌍으로 묶어 다닌다고 생각하면 됨.
- 특징 개수는 유지하 되, 사이즈를 줄여서 중요 특징만 남기도록 압축시킴.
- MaxPooling의 경우, 단순히 요약 역할이지 은닉층이 아님.
- strides = 2 가 기본값.
MaxPooling2D(pool_size=(2,2), strides=(2,2))
- pool_size : 풀링 크기 행 X 열
- strides 옵션 : 생략 시 pool_size와 동일
- 출력 데이터 크기 : Input Size // Pooling Size (몫, 나머지 버림)
4) Flatten Layer
- 최종 예측 결과를 뽑기 위해서는 기본 층인 Dense Layer로 연결해야 함.
- 이때, Dense Layer로 연결하기 위해 1차원으로 펼침.
- Flatten() 메서드 수행
- Dense Layer의 경우, Fully Connected로 구성되어 있음.
'AI 시각지능 & 멀티모달' 카테고리의 다른 글
| AI 시각지능 Instance + Semantic Segmentation(이미지 분할) (0) | 2025.11.17 |
|---|---|
| AI 시각 지능 YOLO 모델링 (0) | 2025.11.10 |
| AI 시각 지능 Object Detection(객체 탐지)와 YOLO (0) | 2025.11.10 |