안녕하세요~!
오늘 포스팅은 딥러닝에 대해 간략히 정리해 보겠습니다.
최적의 모델이란, 오차가 가장 적은 모델을 의미하는데요.
최적의 파라미터인 최적의 가중치(Weight)를 찾는 과정을 '딥러닝을 통해 모델을 학습시킨다'라고 표현합니다.
아래 설명에서 좀 더 자세히 살펴보겠습니다!

1. CRISP-DM 프로세스
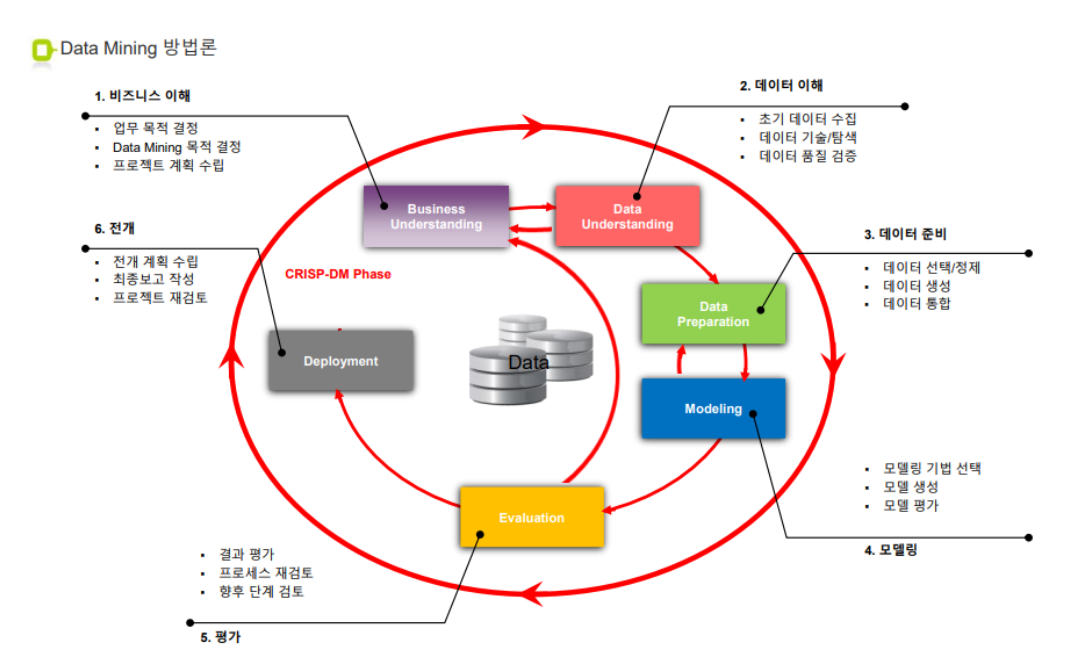
1. 비즈니스 문제 이해
- 비즈니스 문제에 대해 정의
- 데이터 분석 방향과 목표를 설정
- 초기 가설 수립
- x(요인) ----> y(결과)
(여기서 x, y는 모두 정보 즉, 데이터에 해당)
(x = Feature = 요인 / y = Target = Label) => 실무에서는 보통 이와 같이 부르니 기억하자!
2. 데이터 이해
- 원본 식별(내부 / 외부) => 초기 가설에서 도출된 데이터의 근원을 확인하고 취득하는 과정(수집, 구입 등)
- 데이터 분석을 위한 구조(2차원) 만들기
- 데이터 분석 EDA & CDA
(단변량, 이변량 분석 : 산점도 그래프, P-검정 등)
=> 이변량 분석의 경우, 2개 변수 간의 이 가설(x -> y)이 진짜인지 검증
3. 데이터 전처리
- 모델링을 위한 데이터 구조 만들기
- 결측치(NaN값) 제거 => 비즈니스 관점에서 따져보고 신중하게 삭제해야 함!!(주의)
- 모든 값은 숫자로(가변수화)
- 숫자 범위 일치(스케일링) => 딥러닝에서는 빠른 최적화를 위해 스케일링 필수
4. 모델링
- 모델 만들고 검증 진행
5. 평가 및 배포
- 기술적 관점(오차가 얼마나 줄었는지?)과 비즈니스 관점(수익이 늘었는지?)에서 평가 진행
- 결론적으로 해당 모델을 통해 비즈니스 문제가 해결되었는지 점검 필수
2. 딥러닝 개념 - 가중치 조정
- 딥러닝은 조금씩 weight를 조정하며 오차가 줄어드는지 확인
- 지정 epoch 수만큼 학습하거나 더 이상 오차가 줄어들지 않을 때까지 학습시킴.
- 오차의 경우 손실함수(loss function)로 계산
* '학습한다'의 의미
- 데이터 안에 담겨 있는 패턴을 찾음.
- 패턴 = 가중치 = 파라미터
=> 결론적으로 오차를 최소화하는 파라미터(가중치) 값을 찾는다는 의미
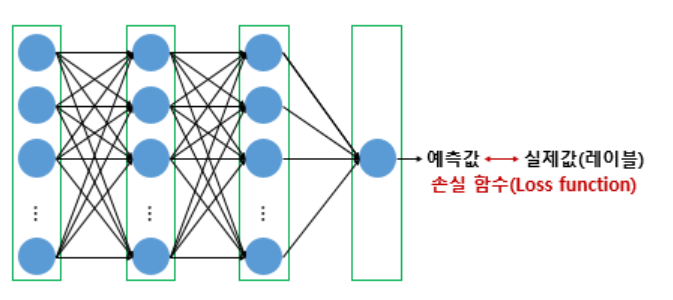
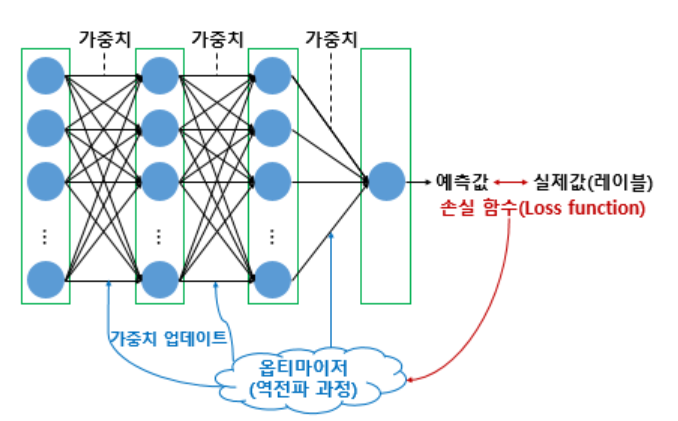
* 학습 절차
1) 가중치에 값 할당
- 초깃값의 경우에는 랜덤으로 지정됨.
2) 예측 결과를 뽑음.
- 모델을 수학식으로 생각해 볼 수 있는데, 이 수학식을 계산하여 예측 결과를 도출하는 과정
3) 오차 계산 (실제값 - 예측값)
- mse(평균 제곱 오차), binary_crossentropy(이진분류), categorical_crossentropy(다중분류) 등 모델에 맞는 손실 함수 적용
- 손실 함수는 실제값과 예측값의 차이를 수치화해 주는 함수
4) 오차를 줄이는 방향으로 가중치 조정
- Optimizer가 가중치를 조정(경사하강법, Adam 등)
- learning_rate(학습 조정 비율) : 업데이트할 비율 / 기울기에 곱해지는 조정 비율 (걸음걸이의 '보폭'을 조정함)
5) 다시 1)로 올라가 반복
3. 딥러닝 구조 & 순전파 / 역전파 개념
- 순전파는 입력층에서 출력층으로 향하면서 가중치를 업데이트하는 방식
- 반대로 역전 파는 출력층에서 Error(MSE)로부터 역으로 입력층 방향으로 올라가며 계산하면서 가중치를 업데이트
- Input은 Layer(X) => 입력되는 x의 분석단위
- Layer 안에 노드(= 뉴런 = 하나의 정보) 들로 구성됨
- Input -> Hidden Layer.... -> Output Layer -> Output (순전파 방향) <--->역전 파는 반대

4. 딥러닝 코드
1) Input(shape = ( , ))
- 입력층
- 분석 단위에 대한 shape
- 하나의 행이 예측단위임. 즉, 하나의 행이 몇 개의 칼럼(feature)으로 이루어져 있는지 세면 됨.
- 1차원 : (feature 수, )
- 2차원 : (rows, columns)
2) Output : Dense( )
- 예측 결과가 1개 변수
- 출력층
3) 컴파일 Compile
- 선언된 모델에 몇 가지 설정 후 컴퓨터가 이해할 수 있는 형태로 변환
* optimizer 지정(learning_rate)
- 오차 최소화하도록 가중치 업데이트 해주는 역할
- 가장 성능이 좋은 옵티마이저인 Adam을 주로 사용
=> GD(경사하강법)로부터 발전한 것이 Adam
* metrics 평가 지표
* loss 오차 함수(=목적함수) --> 오차 최소화의 목적
- 회귀 : MSE
- 분류 : binary_crossentropy, sparse_categorical_crossentropy , categorical_crossentropy
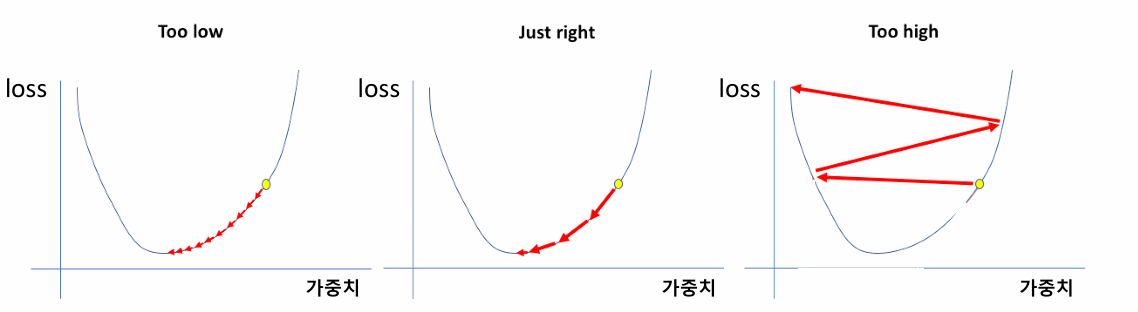
* learning_rate(학습률 조정)
- 가중치를 얼마나 조절할지
값이 너무 작으면 가중치가 조금만 조정되어 최솟값에 도달하지 못할 수 있음.
값이 매우 크면 가중치가 너무 크게 조정되어 오차가 들쑥날쑥하게 됨.
4) 학습 fit
* epochs (학습 반복 횟수)
- 지정한 에폭 수만큼 주어진 train set을 반복 학습
=> 반복학습 하면서 최적의 가중치를 찾아나감
=> 가장 최적의 에폭 수 찾아나갈 수 있음.
* validation_split = 0.2
- train 데이터에서 20% 검증 set으로 분리
* batch_size = 32(기본값)
- 배치 단위로 학습하며 가중치 업데이트 (배치 한 덩어리씩 학습 후 가중치 업데이트 ---> 다시 한 덩어리 학습 후 업데이트.....)
- 전체 train 데이터를 적절히 batch_size만큼 나누어 학습 진행
* .history
- 학습을 수행하는 과정 중에 가중치가 업데이트되면서 계산된 오차 기록들
- 이 history들을 차트로 그리면 학습 곡선이 됨.
5) 학습 곡선
- 모델이 잘 학습되었는지 학습 경향을 파악하기 위한 그래프
- 정답은 아니지만, 바람직하게 학습했는지 판단할 수 있는 도구 중 하나
각 에폭마다 train error(loss)와 val error(val_loss)가 어떻게 줄어들고 있는지 확인 가능
바람직한 학습 곡선은 초기 에폭에서는 오차가 크게 줄고, 오차 하락 폭이 점점 꺾이면서 완만해지는 형태

6) Hidden Layer (은닉층)
- 은닉층에서의 Activation(활성) 함수는 보통 'relu' 사용
* 활성화 함수
- 현재 레이어(각 노드)의 결괏값을 다음 레이어에 어떻게 전달할지 결정 / 변환해 주는 함수
- 히든 레이어를 아무리 추가해도 => y = ax + b 형태의 선형회귀임.
(선형회귀의 경우 어디를 잘라도 다 같은 기울기)
- 선형 모델 ------> 비선형 모델로 변환해 주기 위해 활성화 함수 사용(은닉층)
- 출력층에서는 활성화 함수를 통해 결괏값을 다른 값으로 변환해 줌.
ex. 이진분류에서 출력층 활성화 함수 sigmoid
sigmoid를 통해 0~1 사이 확률 값 변환 후, np.where(pred >= 0.5, 1, 0)를 사용하여 1 OR 0으로 값 도출
ex2. 다중분류에서 출력층 활성화 함수는 softmax
다중분류에서 출력층의 노드 수 = 다중분류 class 수
각 class 별 예측 결과 확률값 모두 더하면 합이 1이 됨.
class 개수 n개 중 누가 1인지 찾음. => 실제 값이 1인 클래스와 예측 값 서로 비교
각 클래스 중 가장 확률값이 큰 값의 인덱스로 변환 : np.argmax(axis=1)
pred = model.predict(x_val)
pred1 = pred.argmax(axis=1)
* y값에 대한 전처리
<1> 정수 인코딩
손실함수 : sparse_categorical_crossentropy
<2> One-hot Encoding
손실함수 : categorical_crossentropy
(정수 인코딩 후 ---> 원-핫 인코딩까지 진행)
