안녕하세요~!
이번 포스팅은 Langchain에 대해 포스팅해보려고 합니다.
Langchain의 개념과 프롬프트를 활용하여 LLM 응답을 받아와 구조화하고 활용하는 방법까지 살펴보겠습니다.

1. LangChain 이란?
- LangChain 은 대규모 언어 모델(LLMs)을 활용하여 체인을 구성하는데, 이 체인을 통해 복잡한 작업을 자동화하고 쉽게 수행할 수 있도록 돕는 라이브러리입니다.
- 허깅페이스 모델, OpenAI 모델, gemini 등 많은 LLM 모델들이 엮여있고, 통합되어 있어서 서로 상호작용이 가능
이를 통해 우리는 여러 모델 쉽게 전환 및 비교가 쉬움.
from langchain_openai import ChatOpenAI
chat = ChatOpenAI(model_name = 'gpt-4.1-mini')
chat.invoke("세계에서 가장 매운 음식은?")
2. 프롬프트(Prompt)란?
- 인간이 인공지능(LLM)에게 전달하는 지시문
- 모델의 응답을 결정짓는 핵심 입력
- LLM에게 무엇을 해야할지 설명하거나 질문, 명령, 조건 제시 등 모두 포함
- LLM의 출력 품질을 좌우하는 가장 중요 요소
LLM으로부터 가장 정확한 응답을 얻기 위해서 질문(프롬프트)을 잘 설계해야 함.
모호한 질문이 아닌 명확한 방향을 제시하는 Prompt가 중요
역할 부여 / 조건 명시 / 맥락 제공이 출력 퀄리티 좌우
3. 답변의 다양성 & 무작위성 제어
1) Temperature(0 ~ 1이상 감정 정도)
- 0 : 가장 보수적이며 항상 같은 답 => 가장 확률이 높은 단어만 선택해서 답변하므로 일관되고 예측 가능
- 1 (1~ ) : 다양하고 창의적인 답변 => 낮은 확률의 단어를 고를 가능성 있어 불안정한 결과
Temperature 값이 0에 가까울수록 항상 일관되고, 냉철한 FM 답변을 하므로 답변 확률 분포가 모여있고 날카로운 형태로 보통 코드를 생성하거나 논리적으로 답변해야 할 때 사용.
Temperature 값이 0.3 ~ 0.7 일 경우, 적당한 창의성을 지닌 답변을 하므로 보통 일상 대화나 설명문에 쓰임.
Temperature 값이 1 이상일 경우, 매우 창의적이므로 답변 확률 분포가 넓게 퍼져있는 형태로 동화같은 이야기, 브레인스토밍, 작사같이 창의성을 요하는 케이스에 사용하면 좋음.
=> LLM은 내부적으로 각 단어 후보마다 로짓(확률 계산 전 실수값인 정규화되지 않은 점수)을 계산한 후,
이를 softmax 함수를 통해 확률로 변환함.
LLM은 확률 분포 기반의 답변 생성 모델이기 때문에, 여러 단어 중 가장 높은 확률의 단어를 선택해서 응답함.
즉, 여러 단어의 확률을 각각 생성하므로 다중분류이고, softmax 함수를 사용함.

2) top_k
- 확률이 가장 높은 K개 단어만 후보로 제한
- 확률 상위 K개 단어만 샘플링 후보
ex) 나는 밤에 -> 다음에 나올 단어를 예측할 때, 확률 분포 기반 샘플링 시 가장 높은 확률의 단어 '잔다.' 가 선택
3) top_p
- 가장 높은 상위 확률의 단어부터 순서대로(내림차순) 누적 확률 총합이 p 이하가 될 때까지 단어가 샘플링 후보가 됨.
- 만약 p가 특정 단어들의 확률 사이 값이라면 다음 단어까지 포함하여 샘플링
* p == 0.85 라면,
A단어(0.8) < P < B단어(0.9)
=> A까지가 아니라, B까지 포함
ex) 아래 케이스에서 p == 0.6이라면,
sunny(0.3) + rainy(0.25) + the(0.1)까지 총 3개 단어가 샘플링 후보

4. LangChain 프롬프트 : ChatPromptTemplate
- 다중 메시지 기반의 프롬프트 흐름을 구성할 수 있도록 도와주는 템플릿
- 프롬프트 -> LLM -> 응답 구조로, 여러 메시지 구조화해서 대화 설계
- 시스템, 사용자, AI 메시지로 구성
1) SystemMessage : AI에게 역할 부여 혹은 성격을 지정 (역할에 따라 답변 방향이 바뀜)
2) HumanMessage : 유저의 질문 혹은 요청 / 맥락 및 목적 부여 & 답변 형식(포맷) 지정
3) AIMessage : AI의 응답
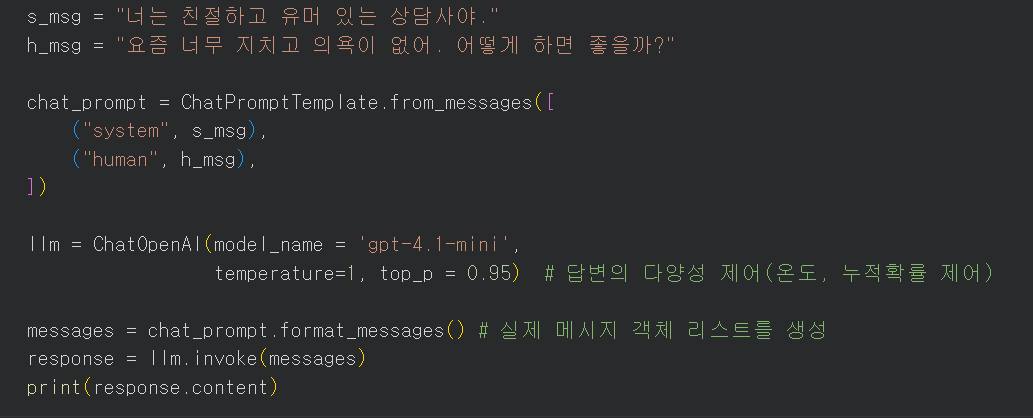
1) chat_pompt = ChatPromptTemplate.from_messages( [
#리스트 안에 튜플 형태의 system, human message를 각각 지정해 줌.
] )
2) messages = chat_pompt.format_messages() -> 구성된 메시지 리스트로 변환
3) response = llm.invoke(messages) -> 앞서 OpenAI로부터 불러온 모델을 사용
4) response.content : 응답 안에 content에 답변이 들어있음.


1) ChatPromptTemplate에서 input_variables 사용
별도로 변수 지정 없이, 메시지 안에 변수 이름 포함
2) s_msg = "너는 {role} 이야."
messages = chat_pompt.format_messages(role="엄마")
5. LLM 응답 구조화 & 활용(출력 통제)
* Output Parser
- LLM은 기본적으로 string 형태로 응답을 반환함.
- string 형태의 데이터 -> 리스트, 딕셔너리, JSON 등 다양한 포맷으로 가공
1) PydanticOutputParser : 텍스트 -> Pydantic 모델로 파싱
- 데이터를 정의하고, 검증할 수 있는 파이썬 라이브러리
- 데이터 구조(스키마) 정의(= 우리가 원하는 형식 틀로 파싱) + 타입이 맞는지 자동으로 검증까지
데이터 구조 정의의 경우, 리스트, JSON 등 다양한 형태로 가능
해당 형태가 맞는지 validation 진행
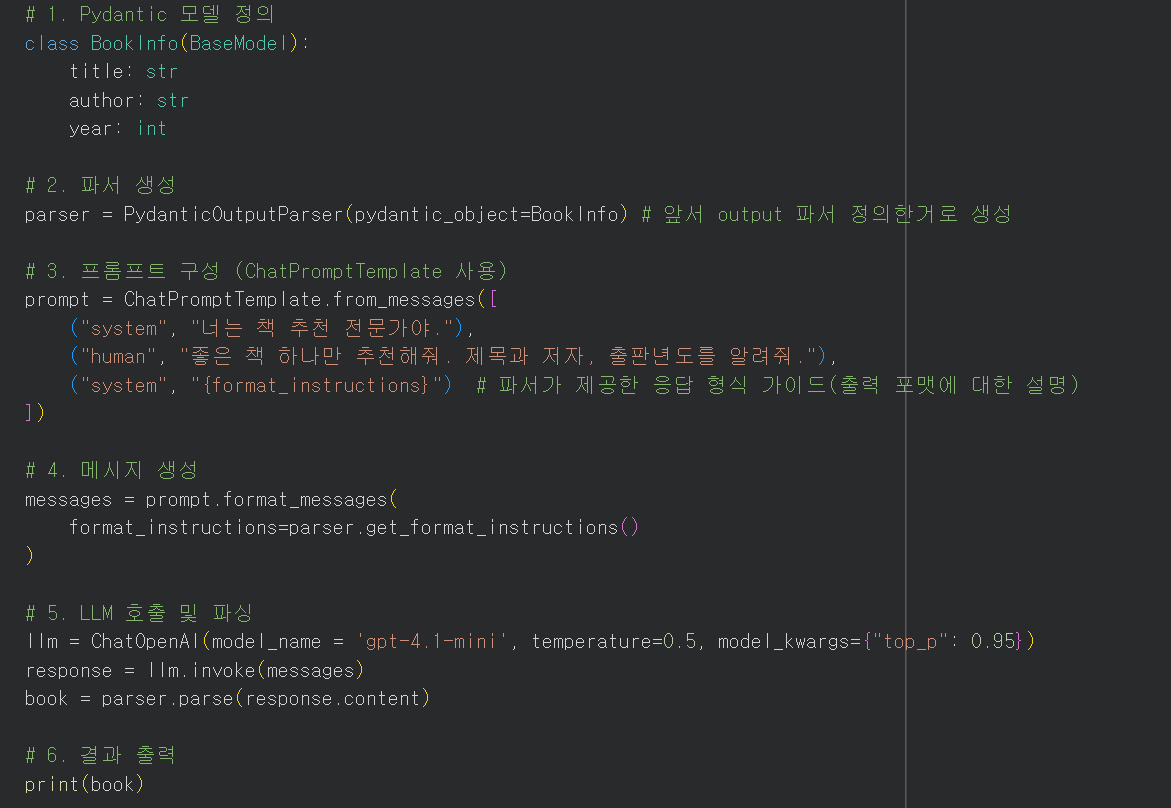

* 파서 생성
parser = PydanticOutputParser(pydantic_object = Pydantic모델)
* 메시지 생성
chat_pompt = ChatPromptTemplate.from_messages( [
("system", "{ format_instructions }")
)]
messages = prompt.format_messages(
format_instructions = parser.get_format_instructions()
)
* llm으로부터 받아온 응답 파싱
book = parser.parse(response.content)
2) CommaSeparatedListOutputParser : 쉼표 구분 문자열 -> 리스트
3) StructuredOutputParser : Json 기반 구조화 파싱
'NLP 자연어처리' 카테고리의 다른 글
| Langchain Memory 종류 (0) | 2025.11.03 |
|---|---|
| LoRA 기반 파인 튜닝 (0) | 2025.10.30 |
| 자연어 처리(NLP) 개념 정리 및 파인튜닝 (0) | 2025.10.26 |